释放双眼,带上耳机,听听看~!
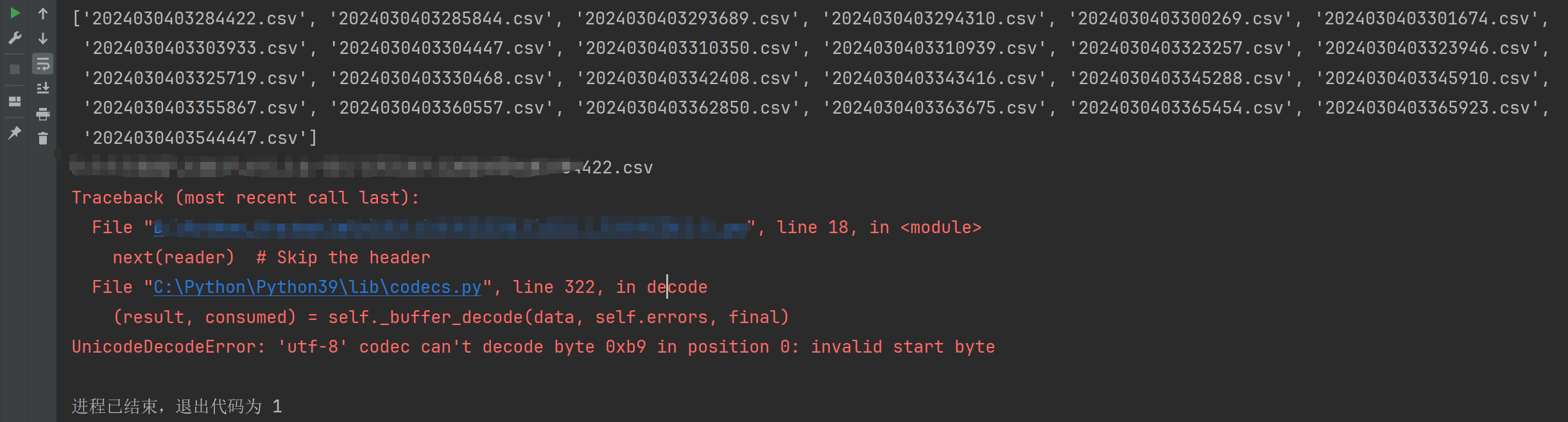
今天在使用Python csv模块的时候,出现了这个错误,不过应该打开其他类型的文件,例如txt文件没指定正确的编码应该也会出现这个问题,可以一起参考下文章里面的解决方法,详细报错信息如下:
Traceback (most recent call last):
File "你的Python文件路径***.py", line 18(代码所在位置), in <module>
next(reader) # Skip the header
File "C:\Python\Python39\lib\codecs.py", line 322, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb9 in position 0: invalid start byte错误原因
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xb9 in position 0: invalid start byte 百度直接翻译后意思是:UnicodeDecodeError:“utf-8”编解码器无法解码位置0中的字节0xb9:无效的起始字节。
导致这个错误出现的原因就是你打开的文件出现的字节“utf-8”编解码器无法解码,所以出现了这个错误,通常是因为我们打开文件的时候指定了utf-8编码或者是默认的编码是utf-8,但是打开的文件不是utf-8编码的,所以就会报错了。
错误解决
指定编码
对打开文件指定对应的编码格式:
在国内的话,一般就是GBK比较多了,Windows默认是gbk,所以打开一些文件会这样
示例代码
with open(you_file_path, 'r', encoding='gbk') as f:
f_content = f.read()
pass忽略错误字符
如果你确认文件对应的编码没错,又出现了类似的错误,则可以在打开文件的时候使用errors=’ignore’参数,来忽略包含无效编码的字符。尝试避免这个错误
示例代码
with open(you_file_path, 'r', encoding='utf-8', errors='ignore') as f:
f_content = f.read()
pass如果你的文件可能包含BOM,那么可以使用utf-8-sig编码打开文件,如果没有则使用utf-8就足够了。
比较详细的解释请你看:在Python中打开文件使用utf-8-sig和utf-8的区别
报错截图