-
Python使用 pytesseract 进行图片识别
在编写爬虫的时候,如果遇见参数图片化的情况的(例如登录验证码),就需要对图片验证码进行识别,我们就可以使用pytesseract。 pytesseract简介 pytesseract是一款用于光学字符识别(OCR)的python工具,即从图片中识别出和“读取”其中嵌入的文字。 底层使用的是Google的Tesseract-OCR 引擎(Tesseract是一个开源文本识别 (OCR) 引擎(注意:…... 塵風
塵風- 0
- 0
- 2k
-

使用Python批量检查网站友情链接
外链对SEO的重要性到今天我想已经不用多说了,友情链接则是我们在优化过程中毕竟经常使用的一种增加外链方法,不过外链还是需要定期的检查的,毕竟一些站长下链卖站了可能不一定会提醒...或者有的网站已经不续费了,域名过期被抢注,直接做灰黑产业站点,我们又没下链,那么排名可能就会直接消失..哈哈哈,但是我们网站多了,又不可能一个个人工去检查,像我之前公司以前SEO订单多的时候要优化100+站点,自己又有一…...- 塵風
- 0
- 0
- 196
-
python模块requests参数stream
使用python requests模块下载大文件时,建议使用strea模式. 默认情况下是false,他会立即开始下载文件并存放到内存当中,倘若文件过大就会导致内存不足的情况. 当把get函数的stream参数设置成True时,它不会立即开始下载,当你使用iter_content或iter_lines遍历内容或访问内容属性时才开始下载。需要注意一点:文件没有下载之前,它也需要保持连接。 iter_…...- 塵風
- 0
- 0
- 618
-
Python字典按照值(value)的大小进行排序方法
Python字典按照值(value)的大小进行排序可以使用collections的Counter()函数和sorted函数两种方式进行,关于Counter和sorted函数之前也记录过,关于这两个详细的就不说了,有需要可以自己看看: python Counter()函数介绍 - 统计值出现的次数 Python3 sorted() 函数 - 对所有可迭代的对象进行排序操作。 下面我们直接看使用它们对…...- 塵風
- 0
- 0
- 486
-
网站被黑,被搜索引擎收录垃圾信息删除处理教程
现在有非常多的站点被黑导致网站被搜索引擎收录了许多的色情、赌博信息,导致网站被降权,或者搜索品牌词的时候出现的站点信息变成了垃圾信息等情况,尽管有的企业不依赖SEO转化,但是品牌词有搜索量的公司遇见这种情况也是比较重要的问题。 注意:这篇文章是教你怎么处理/删除:被搜索引擎收录垃圾信息,而不是教你处理网站被黑(至于网站被黑这问题怎么处理,则太宽泛了,问题原因数不胜数,不是一篇文章说的清楚的)。 处…...- 塵風
- 0
- 0
- 744
-
Python glob模块和主要方法
概述 glob是python自己带的一个文件操作相关模块,查找文件目录和文件,类似于Windows下的文件搜索。 glob模块会将查找到的文件目录或文件的搜索结果返回到一个列表中。 支持的通配符: 支持:*,?,[],这三个通配符 *代表匹配0个或多个字符?代表匹配任意一个字符[]匹配指定范围内的字符如:[0-9]匹配所有数字[a-z]匹配所有字母[1,2,3]仅匹配1,2,3三个数字[!1,2,…...- 塵風
- 0
- 0
- 1.5k
-
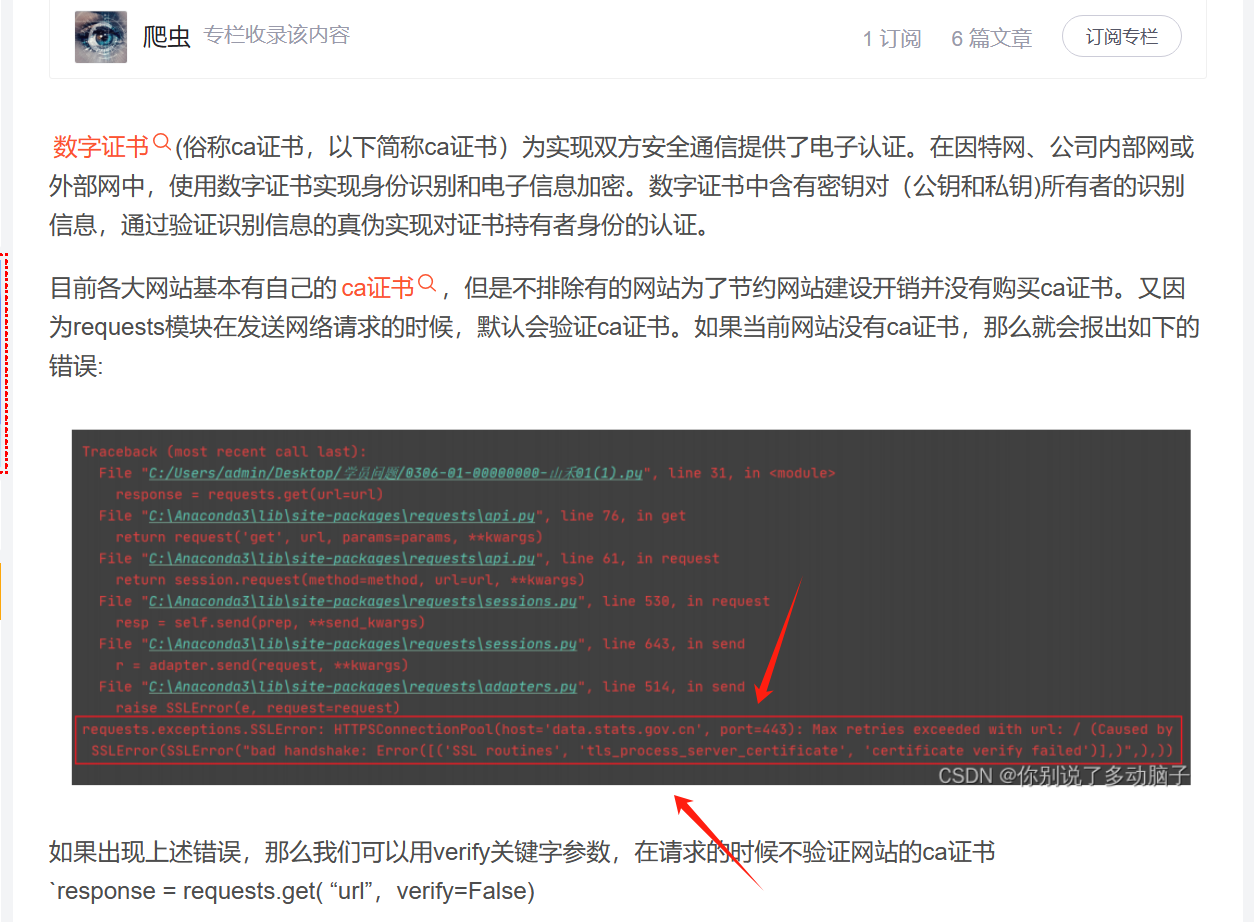
Python模块requests参数verify – SSL证书认证
Python模块requests参数verify - SSL证书认证 requests模块中verify关键词参数用于控制是否开启SSL证书认证,requests在请求HTTPS链接时,默认是开启SSL证书认证的,即请求中verify参数默认为True(verify=True)。 关闭SSL证书认证 如果要关闭SSL证书认证,我们可以把verify参数设置False即可,例如: # -*- cod…...- 塵風
- 0
- 0
- 486
-
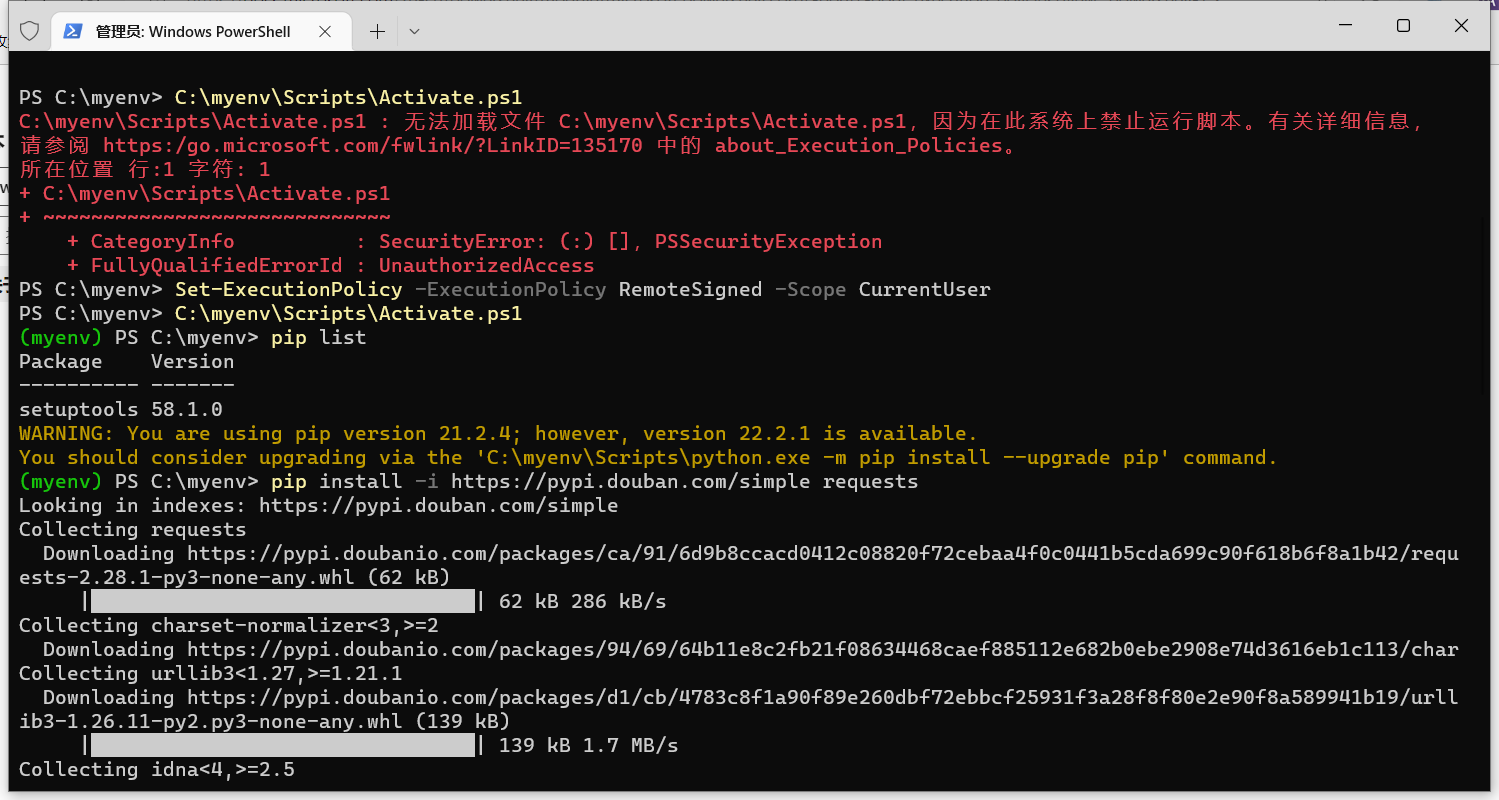
power shell 激活python虚拟环境报错:无法加载文件 *.ps1,因为在此系统上禁止运行脚本。有关详细信息,请参阅 …
在使用python虚拟环境的时候,使用power shell 激活虚拟环境的过程中,出现报错: 报错信息 无法加载文件 *.ps1,因为在此系统上禁止运行脚本。有关详细信息,请参阅 https:/go.microsoft.com/fwlink/?LinkID=135170 中的 about_Execution_Policies。 解决方案 管理员打开PowerShell执行Set-Executio…...- 塵風
- 0
- 0
- 1.5k
-
Python reversed 函数 – 对序列进行逆序操作
Python reversed 函数是一个Python内置函数,它可以对序列进行逆序操作。 序列可以是列表、元组、字符串等,通过使用reversed()函数,我们可以快速简便地将序列中的元素进行逆序排列。我们也可以用它来实现for循环反向遍历。 reversed()函数语法 reversed(sequence) 参数 sequence即是要进行逆序操作的序列( tuple, string…...- 塵風
- 0
- 0
- 147
-
python chardet模块
chardet是什么 chardet是python的一个第三方编码检测模块,chardet 提供自动检测字符编码的功能,可以检测文件,XML等字符编码的类型。通过pip install chardet安装使用。 使用chardet检测编码非常容易,chardet支持检测中文、日文、韩文等多种语言。 chardet.detect() 函数接受一个参数,一个非unicode字符串, 它返回一个字典, …...- 塵風
- 0
- 0
- 1.7k
-
Python获取字典的前x个元素
Python获取字典的前*个元素我们可以使用itertools中的islice函数实现或者是sorted函数、Counter(dict).most_common()函数实现,再Python中列表实现这样的需求就很简单,我们可以直接通过切片获取,不过字典没有切片,我们就先取出所有 keys,再用拿到的key去取value,在组成一个新的字典就可以了。 注意: sorted函数、Counter(dic…...- 塵風
- 0
- 0
- 633
-

python os.scandir()函数
概述 在 Python 3.5版本中,新添加了 os.scandir()方法, scandir是一个目录迭代方法,返回一个DirEntry迭代器对象,它能告诉你迭代文件的路径。 os.scandir() 的运行效率要比 os.walk 高。 在 PEP 471 中,Python 官方也推荐我们使用 os.scandir() 来遍历目录。 相关文章:Python os.walk() 方法 官方介绍截…...- 塵風
- 0
- 0
- 1.5k
-
![Python requests 异常Max retries exceeded with url: 请求地址… (Caused by SSLError(SSLCertVerificationError(1, ‘[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1129)’)))”))}解决](https://www.linfengnet.com/wp-content/uploads/2024/01/2024010606414043.png)
Python requests 异常Max retries exceeded with url: 请求地址… (Caused by SSLError(SSLCertVerificationError(1, ‘[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1129)’)))”))}解决
今天在写爬虫的时候遇见了如下错误: Max retries exceeded with url: https://******... (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get …...- 塵風
- 0
- 0
- 358
-
Python虚拟环境使用
虚拟环境是独立的Python环境,在虚拟环境中通过安装第三方库,不会影响到本地的Python环境或者是其他虚拟环境,这样可以再不同项目对库的版本有不同需求的时候方便我们的使用。 笔记来源内容: 虚拟环境和包 — Python 3.9.13 文档 参考请注意python版本是否相同,其他版本的文档我没看过。 网上还找到了更加详细的虚拟环境相关内容,感兴趣可以自行前往查看: 最全的Python虚拟环境…...- 塵風
- 0
- 0
- 1k
-
Python wmi模块 获取电脑CPU、网卡、硬盘等信息
模块介绍 WMI介绍 Windows Management Instrumentation 翻译过来是Windows 管理规范,简称WMI,是基于 Windows 的操作系统上管理数据和操作的基础结构。 尽管可以编写 WMI 脚本或应用程序来自动执行远程计算机上的管理任务,但 WMI 还会向操作系统和产品的其他部分提供管理数据。 例如,System Center Operations Manage…...- 塵風
- 0
- 0
- 354
-
解决python:AttributeError: ‘set’ object has no attribute ‘items’错误记录
在之前写爬虫代码的时候,我自以为认代码各方面的都没问题了,但是出现了这样一个错误: AttributeError: 'set' object has no attribute 'items' 手动苦笑不得,检查了一遍代码发现都没问题,但是运行还是出现这个错误,于是我就果断百度了下, 出现这个错误可能是我们把一组dict,用逗号相隔了 例如{“id”,id}应…...- 塵風
- 0
- 0
- 1.6k
-
Python从路径|URL中获取文件名、文件后缀的方法
Python从路径|URL中获取文件名、文件后缀的方法分享: 我们可以通过urlparse模块中的urllib.parse方法、os.path模块或者是字符串split、rfind等方法去实现,非常简单。这样就不用去写正则了哈哈哈。 一般情况下urlparse更合适解析URL(URL中有参数的时候,不需要做其他处理),os.path模块则更合适处理本地路径,所以大部分时候个人建议选择这两种方式也就…...- 塵風
- 0
- 0
- 933
-
python转换Unix时间戳
python 转换Unix时间戳可以使用python中的time模块和datetime模块 time # -*- coding: utf-8 -*- import time # new_date = time.ctime(Unix时间戳) new_date = time.ctime(1567764428) print(new_date) # Fri Sep 6 18:07:08 2019 date…...- 塵風
- 0
- 0
- 1.3k
-
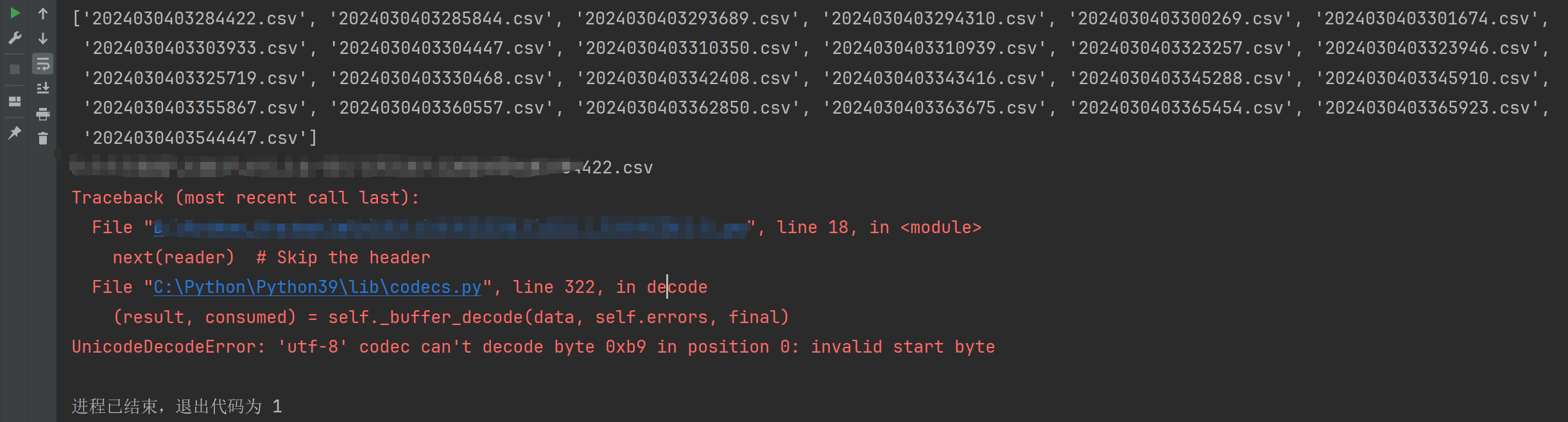
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xb9 in position 0: invalid start byte错误解决
今天在使用Python csv模块的时候,出现了这个错误,不过应该打开其他类型的文件,例如txt文件没指定正确的编码应该也会出现这个问题,可以一起参考下文章里面的解决方法,详细报错信息如下: Traceback (most recent call last): File "你的Python文件路径***.py", line 18(代码所在位置), in <module&g…...- 塵風
- 0
- 0
- 388
-
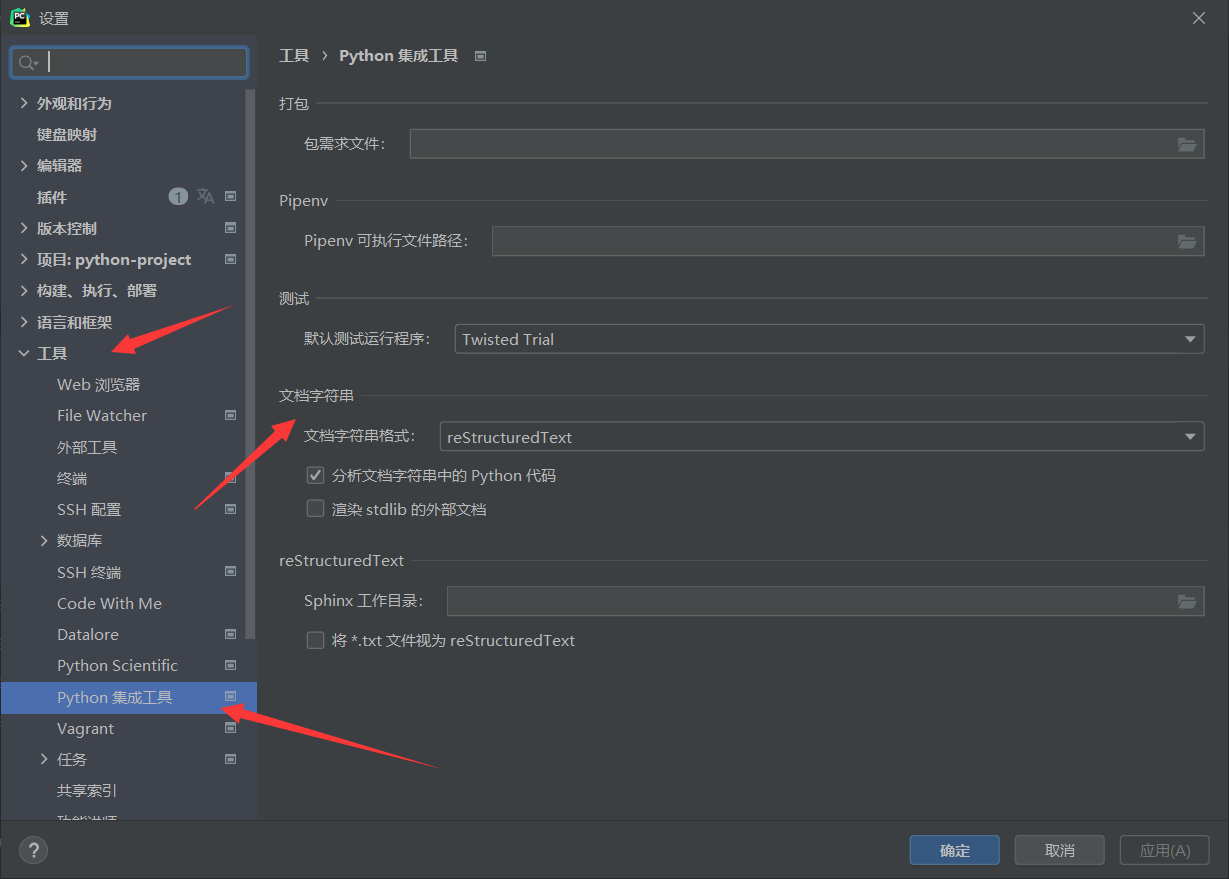
Pycharm函数注释(参数和返回值)无法自动生成问题解决
正常使用Pycharm,对定义的函数书写注释(三个引号),Pycharm是会自动生成函数参数和返回值的注释格式,如下: 问题展示 # 定义一个函数 def test(a, b): """ # 再输入三个引号(单引号和双引号均可)后回车,会自动生成函数参数和返回值的注释 pass 正常情况: 输出结果为 def test(a, b): '''…...- 塵風
- 0
- 0
- 1.5k

-
¥优惠劵使用时效:无法使用使用时效:
之前
使用时效:永久有效优惠劵ID:×