-
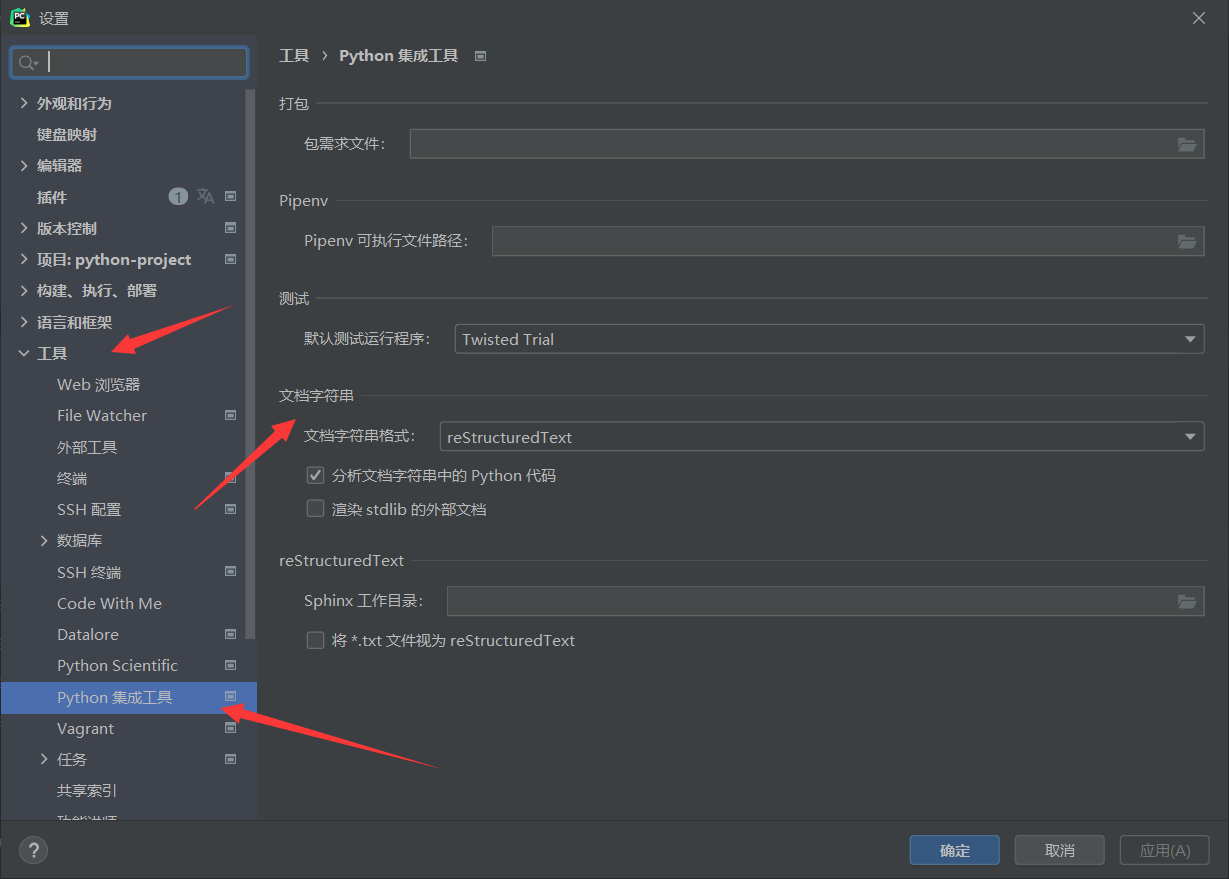
Pycharm函数注释(参数和返回值)无法自动生成问题解决
正常使用Pycharm,对定义的函数书写注释(三个引号),Pycharm是会自动生成函数参数和返回值的注释格式,如下: 问题展示 # 定义一个函数 def test(a, b): """ # 再输入三个引号(单引号和双引号均可)后回车,会自动生成函数参数和返回值的注释 pass 正常情况: 输出结果为 def test(a, b): '''…... 塵風
塵風- 0
- 0
- 1.9k
-

Python拼接URL:urllib.parse urljoin使用
Python拼接URL可以使用urllib.parse中的urljoin方法,urllib是Python中一个用于URL 处理的模块,urllib.parse 用于解析 URL,在之前分享的Python从路径|URL中获取文件名、文件后缀的方法中提到过使用其中的urlparse方法解析URL,感兴趣的可以去看看。 urllib.parse模块的的urlparse和urljoin刚好是两个相反的功能…...- 塵風
- 0
- 0
- 1.1k
-

Python glob模块和主要方法
概述 glob是python自己带的一个文件操作相关模块,查找文件目录和文件,类似于Windows下的文件搜索。 glob模块会将查找到的文件目录或文件的搜索结果返回到一个列表中。 支持的通配符: 支持:*,?,[],这三个通配符 *代表匹配0个或多个字符?代表匹配任意一个字符[]匹配指定范围内的字符如:[0-9]匹配所有数字[a-z]匹配所有字母[1,2,3]仅匹配1,2,3三个数字[!1,2,…...- 塵風
- 0
- 0
- 1.9k
-
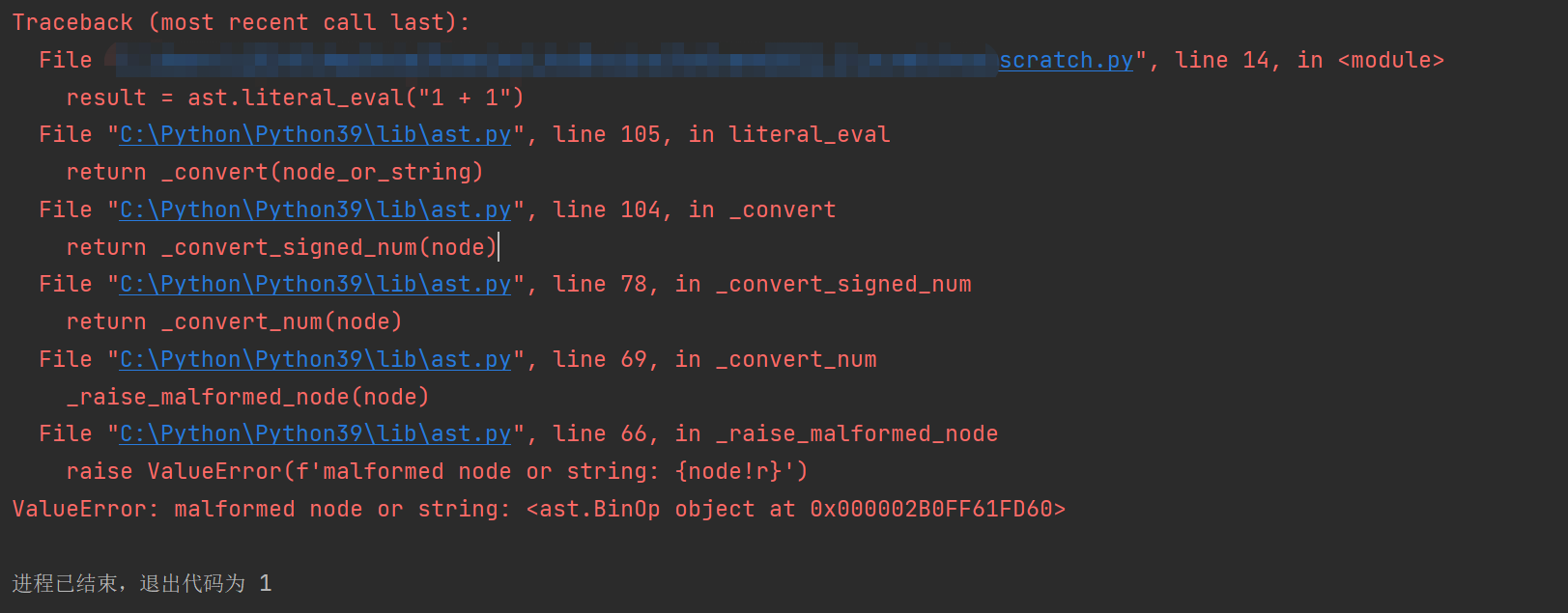
Python 将字符串转为字典
Python 将字符串转为字典可以使用ast模块中的literal_eval方法或者是json模块、eval方法。下面分享下这三种方法的示例代码: 注:虽然上面列举了三个在Python中可以实现将字符串转为字典的方法,但是推荐使用ast模块中的literal_eval方法进行,具体的原因会在下述说明,下面是详细的代码: 通过 json 来转换 我们可以直接使用json模块中的loads函数对字符串…...- 塵風
- 0
- 0
- 768
-
Python3 sorted() 函数 – 对所有可迭代的对象进行排序操作
sorted() 函数描述 Python3 sorted() 函数是python 3 中的一个内置函数,sorted() 函数作用是可以对所有可迭代的对象进行排序操作。 PS:有时候我们需要对拿到的字典之类的数据进行排序,就可以直接使用这个函数,而不需要进行for循环这样的操作去处理啦,如果数据是列表的话,也可以使用sort()函数,具体可以看我之前的文章:python sort()函数详解。 s…...- 塵風
- 0
- 0
- 1k
-
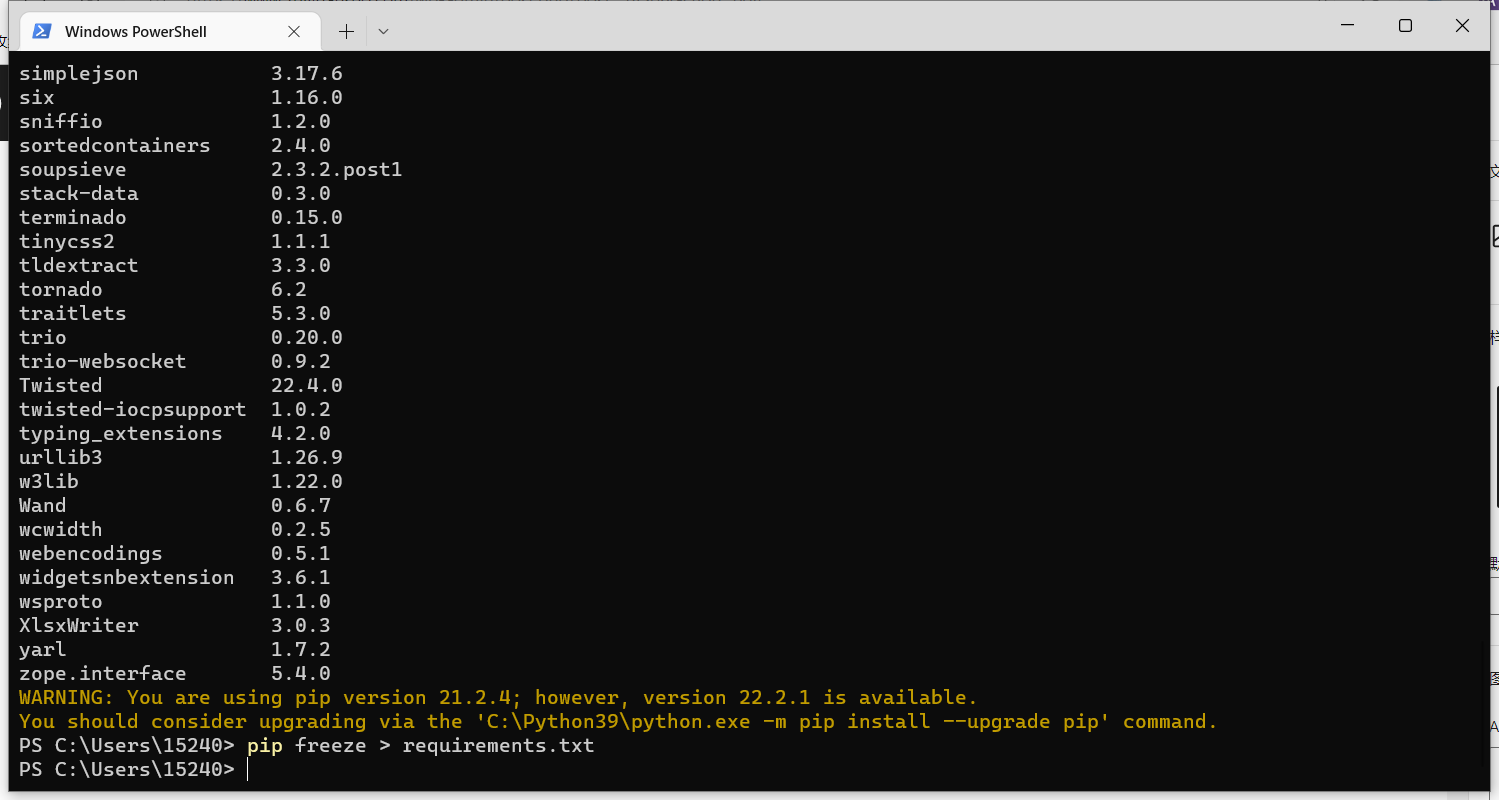
Python虚拟环境使用
虚拟环境是独立的Python环境,在虚拟环境中通过安装第三方库,不会影响到本地的Python环境或者是其他虚拟环境,这样可以再不同项目对库的版本有不同需求的时候方便我们的使用。 笔记来源内容: 虚拟环境和包 — Python 3.9.13 文档 参考请注意python版本是否相同,其他版本的文档我没看过。 网上还找到了更加详细的虚拟环境相关内容,感兴趣可以自行前往查看: 最全的Python虚拟环境…...- 塵風
- 0
- 0
- 1.4k
-
Python wmi模块 获取电脑CPU、网卡、硬盘等信息
模块介绍 WMI介绍 Windows Management Instrumentation 翻译过来是Windows 管理规范,简称WMI,是基于 Windows 的操作系统上管理数据和操作的基础结构。 尽管可以编写 WMI 脚本或应用程序来自动执行远程计算机上的管理任务,但 WMI 还会向操作系统和产品的其他部分提供管理数据。 例如,System Center Operations Manage…...- 塵風
- 0
- 0
- 979
-

python os.scandir()函数
概述 在 Python 3.5版本中,新添加了 os.scandir()方法, scandir是一个目录迭代方法,返回一个DirEntry迭代器对象,它能告诉你迭代文件的路径。 os.scandir() 的运行效率要比 os.walk 高。 在 PEP 471 中,Python 官方也推荐我们使用 os.scandir() 来遍历目录。 相关文章:Python os.walk() 方法 官方介绍截…...- 塵風
- 0
- 0
- 1.8k
-

Python enumerate() 函数,Python将列表转换为索引:元素的字典
Python将列表转换为索引:元素的字典可以使用Python enumerate() 函数,enumerate() 函数是Python中的一个内置函数。 enumerate() 函数 介绍 enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。 Python 2.3. 以上版本可用,2.6 添加 sta…...- 塵風
- 0
- 0
- 843
-
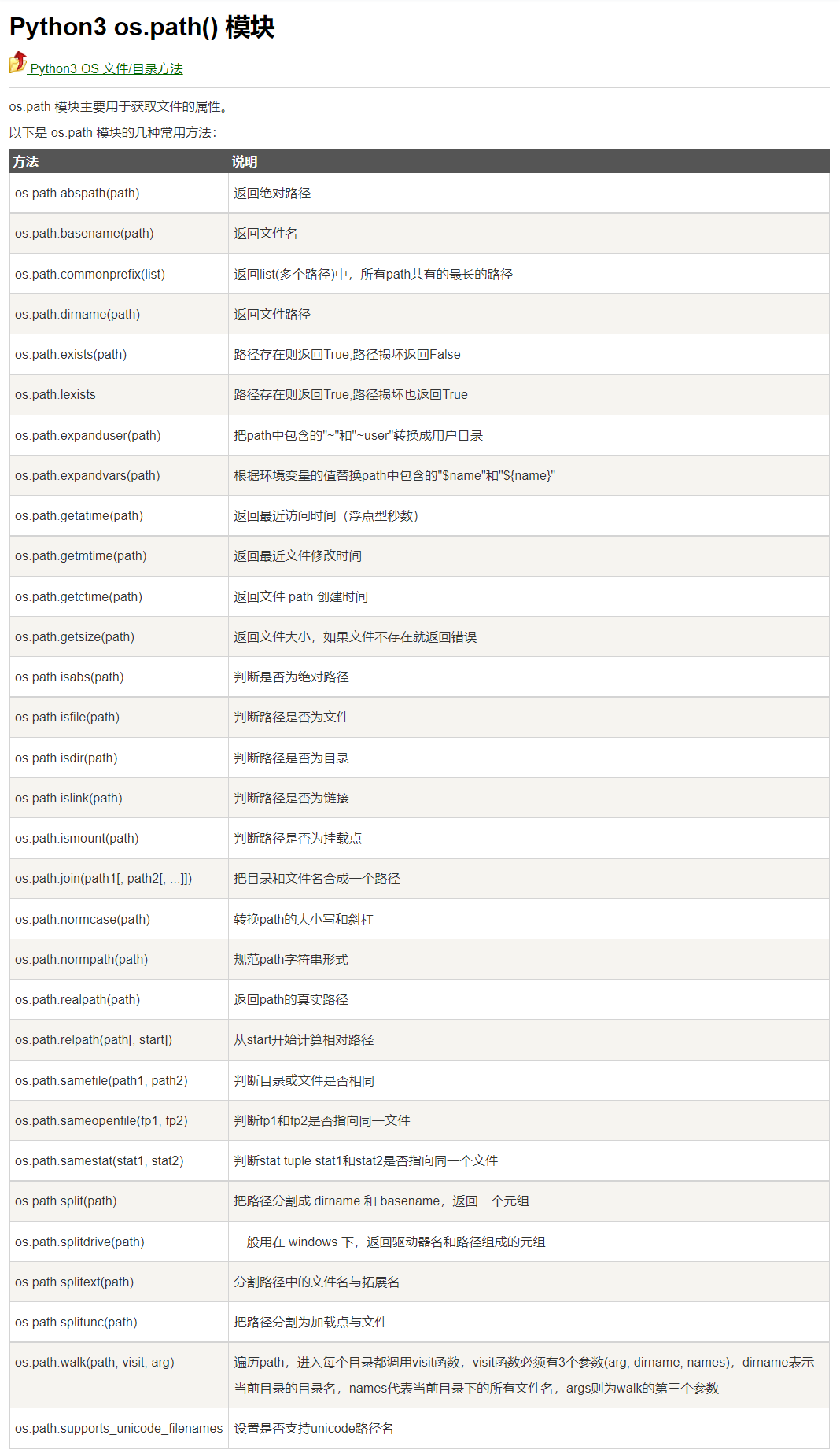
python os.path.dirname(__file__)
os.path.dirname() 是python os.path 模块的一种方法: 作用: 返回文件路径(只是路径 不包含文件名) os.path.dirname(path) # 返回路径path的目录名称 os.path.dirname(__file__) # 直接返回当前文件路径 os.path.dirname()注意点: os.path.dirname() 和os.path.basenam…...- 塵風
- 0
- 0
- 1k
-
Python实现将字符串复制到粘贴板
Python实现将字符串复制到粘贴板方法分享: 一:使用perclip库 安装 pip install pyperclip 示例代码 # 导入pyperclip import pyperclip # 使用pyperclip.copy()方法可以将指定的字符串复制到剪贴板。 text = '这是要复制到剪贴板的文本' pyperclip.copy(text) # 运行代码后 Ct…...- 塵風
- 0
- 0
- 1.2k
-
Python获取字典的前x个元素
Python获取字典的前*个元素我们可以使用itertools中的islice函数实现或者是sorted函数、Counter(dict).most_common()函数实现,再Python中列表实现这样的需求就很简单,我们可以直接通过切片获取,不过字典没有切片,我们就先取出所有 keys,再用拿到的key去取value,在组成一个新的字典就可以了。 注意: sorted函数、Counter(dic…...- 塵風
- 0
- 0
- 1.1k
-
Python pip命令大全
Python pip 使用命令大全分享 官方文档 地址:https://docs.python.org/3/installing/index.html 命令大全 安装模块 pip install 模块名 通常,如果已经安装了模块,再次安装 它再次不会有任何效果。如需要升级 请使用升级命令。 不加版本号 默认安装模块当前最新版本。 安装指定版本 pip install 模块名==1.xx 指定源安装…...- 塵風
- 0
- 0
- 519
-
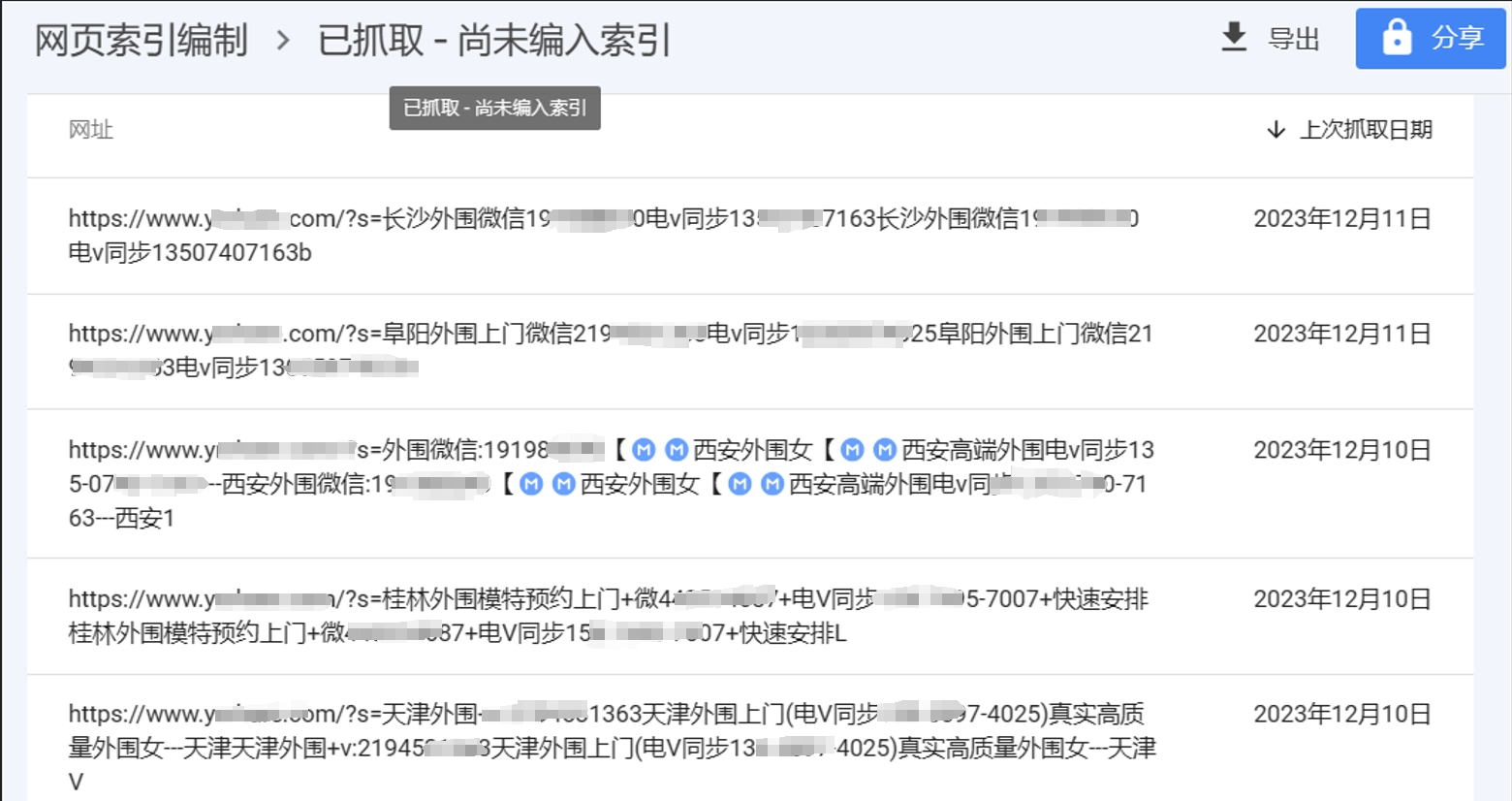
网站搜索页面出现大量垃圾网页被收录怎么处理
网站搜索页面出现大量垃圾网页被收录怎么处理?这个问题是前几天一个朋友问我的,问题示例如下: 问题展示 再说解决方法之前我们先聊聊这个问题出现的原因,原因很明显: 就是网站被模拟搜索了大量的垃圾信息关键词,然后出现了对应的页面让搜索引擎抓取了。 像这种也算是"黑帽SEO"推广了吧...不过我认为这个东西实现起来还是很简单的,技术含量很低,而且挺早之前就出现了。 我可不可以不处理?…...- 塵風
- 0
- 0
- 1.4k
-
使用Python批量检查网站友情链接
外链对SEO的重要性到今天我想已经不用多说了,友情链接则是我们在优化过程中毕竟经常使用的一种增加外链方法,不过外链还是需要定期的检查的,毕竟一些站长下链卖站了可能不一定会提醒...或者有的网站已经不续费了,域名过期被抢注,直接做灰黑产业站点,我们又没下链,那么排名可能就会直接消失..哈哈哈,但是我们网站多了,又不可能一个个人工去检查,像我之前公司以前SEO订单多的时候要优化100+站点,自己又有一…...- 塵風
- 0
- 0
- 557
-
Python os.walk() 方法
概述 os.walk() 方法用于通过在目录树中游走输出在目录中的文件名,向上或者向下。 os.walk() 方法是一个简单易用的文件、目录遍历器,可以帮助我们高效的处理文件、目录方面的事情。 在Unix,Windows中有效。 语法 walk()方法语法格式如下: os.walk(top[, topdown=True[, onerror=None[, followlinks=False]]]) …...- 塵風
- 0
- 0
- 1k
-
Python列表合并的6种方法
Python列表合并的6种方法分享,下面我共列举了6中合并列表的方法,在单个或者少量(3个内?)我们可以直接使用运算符+或者+=或者extend就可以轻松的实现合并,如果列表数量太多,可以考虑使用chain,详细的介绍和示例代码大家往下看吧。 准备数据 首先我们准备三个列表作为测试学习使用数据,下面的代码中不在重复。 # 以三个全是名字元素的列表作为测试数据 name_list_1 = […...- 塵風
- 0
- 0
- 821
-
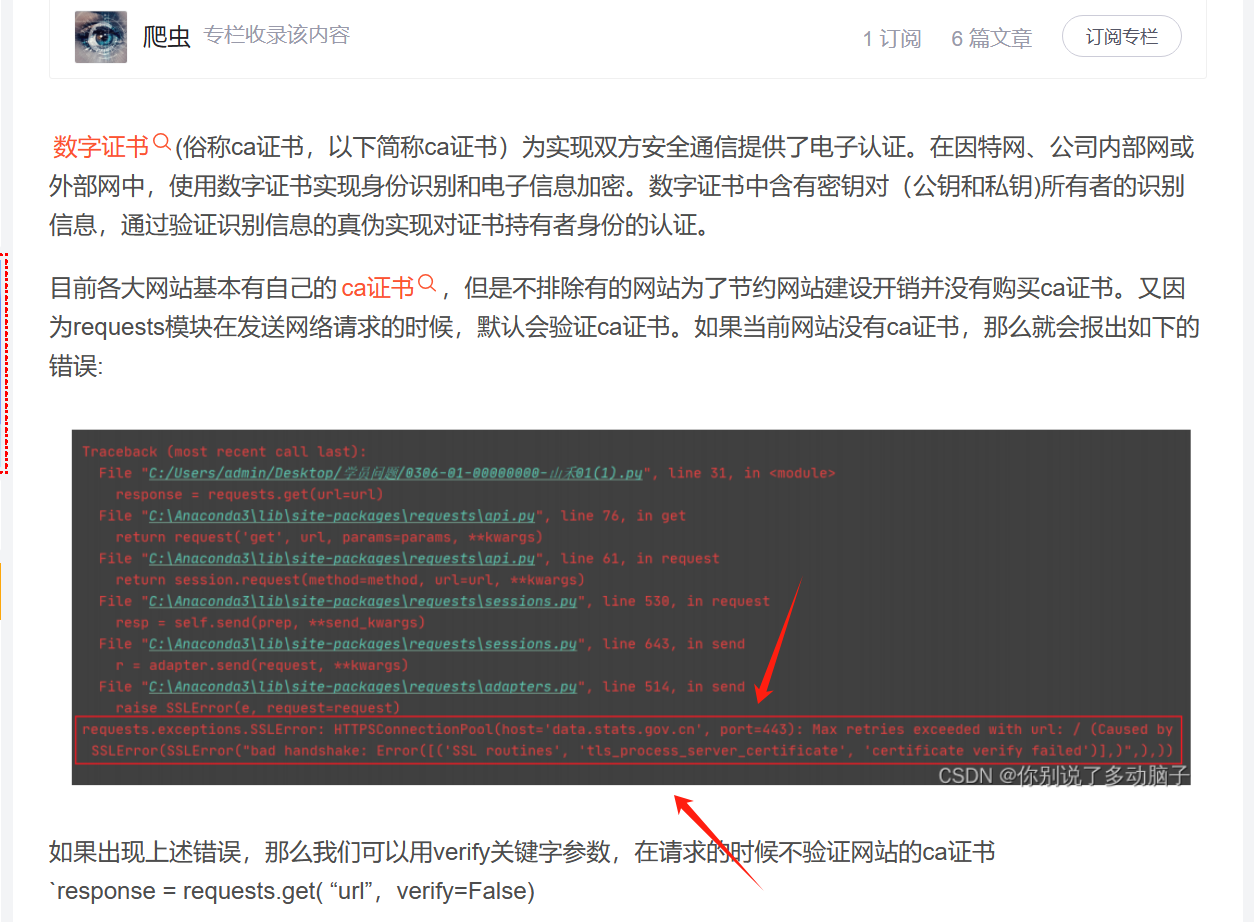
Python模块requests参数verify – SSL证书认证
Python模块requests参数verify - SSL证书认证 requests模块中verify关键词参数用于控制是否开启SSL证书认证,requests在请求HTTPS链接时,默认是开启SSL证书认证的,即请求中verify参数默认为True(verify=True)。 关闭SSL证书认证 如果要关闭SSL证书认证,我们可以把verify参数设置False即可,例如: # -*- cod…...- 塵風
- 0
- 0
- 1k
-
Python如何只导出当前Python文件所需模块包依赖
Python如何只导出当前Python文件所需模块包依赖? 之前在Python虚拟环境使用文章我分享过使用pip freeze导出当前虚拟环境的模块,但是有时候我们写的脚本只需要导出单个文件或者项目目录不是整个虚拟环境的时候,就不行了; 如果只需要导出当前Python文件所需模块包依赖我们可以使用pipreqs模块,下面是pipreqs的使用方法和经验分享: 安装pipreqs库 pip inst…...- 塵風
- 0
- 0
- 1.4k
-
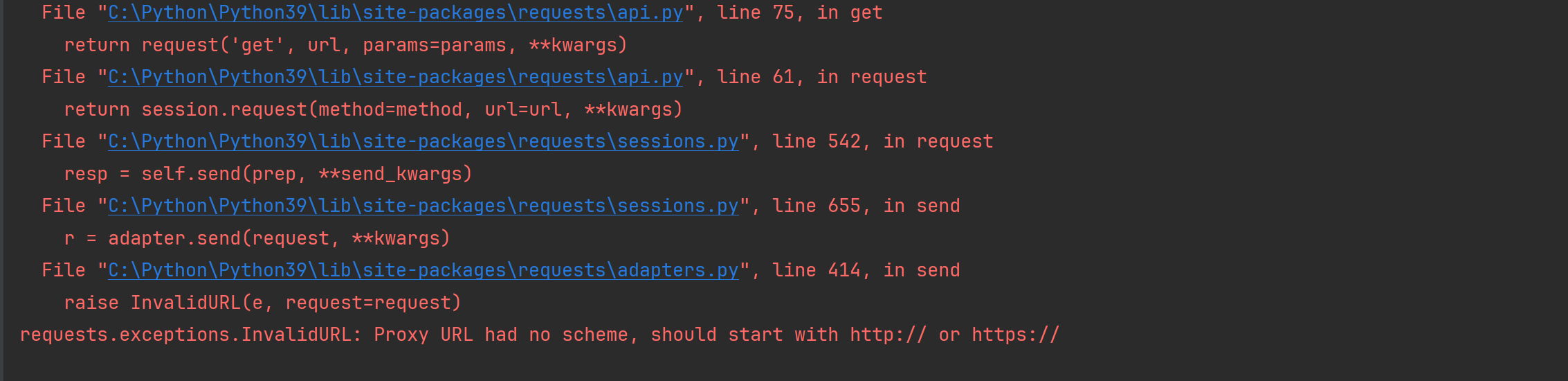
Python requests 异常Proxy URL had no scheme, should start with http:// or https://解决
异常原因 Python requests 异常Proxy URL had no scheme, should start with http:// or https://解决,在使用Python requests的proxy代理功能的时候出现了这个错误,意思是我们使用的代理方案应该以http:// or https://开头。 在网上看到的原因是说在Python3.7及以上版本中使用request…...- 塵風
- 0
- 0
- 945

-
¥优惠劵使用时效:无法使用使用时效:
之前
使用时效:永久有效优惠劵ID:×