-

相似度计算常用方法综述
引言 相似度计算用于衡量对象之间的相似程度,在数据挖掘、自然语言处理中是一个基础性计算。其中的关键技术主要是两个部分,对象的特征表示,特征集合之间的相似关系。在信息检索、网页判重、推荐系统等,都涉及到对象之间或者对象和对象集合的相似性的计算。而针对不同的应用场景,受限于数据规模、时空开销等的限制,相似度计算方法的选择又会有所…... 塵風
塵風- 0
- 0
- 571
-

Boosting算法简介
一、Boosting算法的发展历史 Boosting算法是一种把若干个分类器整合为一个分类器的方法,在boosting算法产生之前,还出现过两种比较重要的将多个分类器整合为一个分类器的方法,即boostrapping方法和bagging方法。我们先简要介绍一下bootstrapping方法和bagging方法。 1)bootstrapping方法的主要过程 主要步骤: i)重复地从…...- 塵風
- 0
- 0
- 506
-
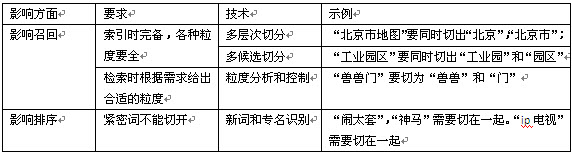
搜索引擎中的粒度问题
一.前言 传统的搜索引擎的定义,是指一种对于指定的查询(Query),能够返回与之相关的文档集合(Documents)的系统。而百度将这个定义更加丰富化,即搜索引擎能够帮助人们更方便的找到所求。这里的“所求”,比“文档”更加宽泛和丰富,比如一个关于天气的查询,直接返回一个天气预报的窗口,而非一篇关于天气的文档;再如一个关于小游戏的查询,直接返回这个小游戏的Flash页面而非简单的介绍性的文字。 百…...- 塵風
- 0
- 0
- 629
-

搜索背后的奥秘–浅谈语义主题计算
摘要: 两篇文档是否相关往往不只决定于字面上的词语重复,还取决于文字背后的语义关联。对语义关联的挖掘,可以让我们的搜索更加智能化。本文着重介绍了一个语义挖掘的利器:主题模型。主题模型是对文字隐含主题进行建模的方法。它克服了传统信息检索中文档相似度计算方法的缺点,并且能够在海量互联网数据中自动寻找出文字间的语义主题。近些年来各大互联网公司都开始了这方面的探索和尝试。就让我们看一下究竟吧。 关键词:主…...- 塵風
- 0
- 0
- 433
-

基于主特征空间相似度计算的切分算法及切分框架
我们为什么要切分? 说到切分(segmentation),大多数人最容易想到的就是中文分词。作为没有天然空格区分的语言,切词可以帮助计算机去索引文章,从而便于信息检索等方面。该部分主要用到了分词的一个方面:降低搜索引擎的性能消耗。我们常用的汉字有5000多个,常用词组是几十万个。在倒排索引中,如果用每个字做索引的话,那么会造成每个字对应的拉链非常长。所以我们一般会用词组来代替单个汉字建立索引。除此…...- 塵風
- 0
- 0
- 396
-
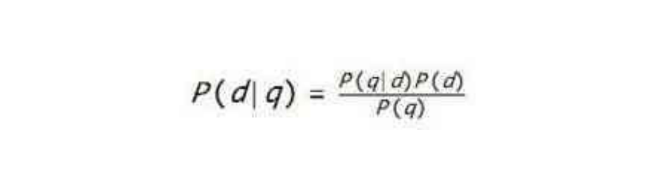
以求医为例谈搜索引擎排序算法的基础原理
我们向搜索引擎提交一个查询,搜索引擎会从先到后列出大量的结果,这些结果排序的标准是什么呢?这个看似简单的问题,却是信息检索专家们研究的核心难题之一。 为了说明这个问题,我们来研究一个比搜索引擎更加古老的话题:求医。比如,如果我牙疼,应该去看怎样的医生呢?假设我只有三种选择: A医生,既治眼病,又治胃病;B医生,既治牙病,又治胃病,还治眼病;C医生,专治牙病。 A医生肯定不在考虑之列。B医生和C医生…...- 塵風
- 0
- 0
- 407

-
¥优惠劵使用时效:无法使用使用时效:
之前
使用时效:永久有效优惠劵ID:×