
一.前言
传统的搜索引擎的定义,是指一种对于指定的查询(Query),能够返回与之相关的文档集合(Documents)的系统。而百度将这个定义更加丰富化,即搜索引擎能够帮助人们更方便的找到所求。这里的“所求”,比“文档”更加宽泛和丰富,比如一个关于天气的查询,直接返回一个天气预报的窗口,而非一篇关于天气的文档;再如一个关于小游戏的查询,直接返回这个小游戏的Flash页面而非简单的介绍性的文字。
百度对Query深刻的理解,源于自然语言处理技术在其中发挥的巨大作用。对搜索引擎而言,文本切分是最基础也是最重要的自然语言问题之一。今天,我们就来谈谈文本切分粒度与搜索引擎的关系。
本文后续章节组织如下:第二节介绍什么是文本的粒度,第三节讲述搜索引擎的基本原理与文本切分粒度的关系,第四节深入探讨粒度的属性与检索相关性计算,第五节小结。
二.文本粒度
什么是文本的粒度?我们用什么来衡量文本粒度?在回答这些问题前,让我们先看看以下几组词汇:
缠绵、崎岖、葡萄、乒乓
绿茶、篮球、红色、鼠标垫、起重机
打球、跳绳、炒菜、登山
笔记本电脑、高清机顶盒、IP电视
但是、然后、如果、非常
步步惊心、家的n次方、一个人的精彩
百度在线网络技术(北京)有限公司、清华大学
张学友、赵传、工藤新一、里奥内尔·安德雷斯·梅西
……
这几组词汇中,哪些的粒度大,哪些的粒度小?
不管在传统的语言学领域,还是在自然语言处理领域,都没有对粒度下一个清晰准确的定义。但是就搜索引擎而言,我们不妨这样定义:粒度是衡量文本所含信息量的大小。文本含信息量多,粒度就大,反之就小。有了这个原则,我们就很容易判断文本粒度大小了。像“缠绵”,“崎岖”,“葡萄”这些词,虽然有两个字组成,但是仅表达一个意思,这些词的粒度是小的。而“篮球”,“鼠标垫”等词,是由简单词合成的,虽然也只有一个意思,但还可以拆分,如“篮”和“球”,“鼠标”和“垫”。这类词,粒度稍微大一些。而“笔记本电脑”,“高清机顶盒”这样的词,粒度就更大了。
专名是一类比较特殊的词,尽管所含字数很多,但其实只表达一个意思,如“步步惊心”,“家的n次方”这样的电影、电视剧的名称,粒度是很小的。机构名、人名等属于有内部结构的专名,比电影名的粒度稍大一些。
显然易见,我们在讨论文本粒度时,理想的方式是从语义角度出发,合理的分析和判断。然而以上我们仅对粒度做了定性的分析,为粒度找一个合适的度量单位和计算方法,是百度人一直追求的目标。
三.搜索引擎的基本原理与词汇切分关系
3.1 搜索引擎的基本原理
文本检索系统,是搜索引擎最简单的实现方式。通过返回包含关键字的页面,来满足用户的检索需求。形式化的表达就是给定一系列关键字集合K,要求返回所有包含关键字的文档D,对D中的任意一个文档d,包含K中的任意一个关键字k。
一般我们采用倒排索引的方式来实现这个系统。所谓倒排索引,就是对关键字建立索引,记录包含这个关键字的文档集合D。对于请求的关键字集合,找出所有关键字对应的索引,并对索引求交,最后返回同时存在于所有索引中的文档。
在百度,我们不仅允许用户输入关键字,也可以输入任何长度在一定范围内的文本。此时我们需要对文本做一定处理,切分成一系列关键字,从而能够从倒排索引中找出对应的文档。
那么为什么要对输入文本做切分,如果不切分会有什么问题?
我们可以想象一下,如果不对输入文本做切分,直接用输入文本去做匹配,会怎么样?首先,得到的结果会非常少,因为直接用全部文本匹配,就失去了灵活性,对结果限制的非常死,必须完全匹配才能满足要求;其次,系统性能会非常差,因为需要对所有长度的文本都建立索引,这是指数级的,在实际系统中根本不可能实现。再考虑一下另一个极端?我们对输入文本做单字切分,结果又是怎样?我们会得到大量无关的页面,不仅浪费系统性能,对相关性计算也造成了巨大的压力。
所以,我们需要对文本做一个合适的切分。
3.2 用户满意度与粒度关系
无论是建立倒排索引、还是处理输入文本,我们都需要对文本做切分,切出合适的关键字出来。为了能够使用户对查询结果满意,搜索引擎需要什么样的粒度?让我们先看一下下面几个例子:
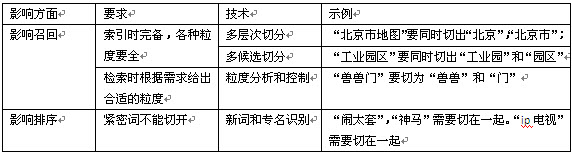
- Q:“北京地图” P1:“北京市地图” P2:“北京城市地图”
- Q:“闹太套是神马意思”, P:”A:神呐,我骑不了这烈马。B:闹太套!”
- Q:“兽兽门” P:“兽兽艳照门”
- Q1:“工业园” Q2:“园区” P:“工业园区”
- Q:“ip电视” P1:“ip电视的历史” P2:“电视销售…您的IP是xxx”
注:Q表示query,P表示页面中包含Q的内容
Case1,要求query能找到P1和P2这样的结果,就必须对P1和P2都切出“北京”这个词来。Case2,必须把”神马”切为一个词,否则会召回P这样不相关的结果。Case3,不能把Q中的“兽兽门“切为一个词,而需要切除“兽兽”,否则就召不回”兽兽艳照门”这个结果。Case4中,对“工业园区”这样的页面,必须同时切出“工业园”和“园区”这两个重叠的词汇,才能保证Q1和Q2都能召回。Case5与Case2类似,如果把ip和电视分开切分,将召回P2这样不相关的结果。
以上几个case,基本上概括了搜索引擎对切分粒度的要求,我们可以从两方面来描述:1)影响召回 2)影响相关性
以上从用户满意度的角度,讨论了搜索引擎与粒度的关系,当然,这是最基本的要求,在第四节我们还会对文本的粒度问题做更深入的分析。
3.3 搜索系统性能与粒度的关系
显而易见,粒度越小,召回就越多,建立倒排索引时,索引的长度就越长;粒度的层次越多,索引的数量就越多。一个多,一个长,就对搜索系统的性能构成了极大的考验。
一般而言,大型搜索引擎的索引都采用分布式系统。不同文本的索引,被某种hash算法“分配”到了某台机器。理论上讲,索引的数量的增长,只会造成所需机器的增长,而对整体系统性能的消耗影响比较小。所以一般搜索引擎会从性价比的角度来考虑索引数量与机器数量的折衷,也就是召回与硬件投入的折衷。粒度分析对于折衷的性价比也有一定的贡献,在粒度层次里,当粒度逐渐变小的过程中,我们并不一定对所有小粒度词都建索引,而是选择“更有可能召回相关结果”的小粒度词。词汇的什么性质决定了“更有可能召回相关结果”?我们同样会在第四节讨论。
四.深入分析粒度的性质
在第三节中我们反复提到:一般情况下,粒度越大,相关性越好,召回越差;粒度越小,相关性越差,召回越好。在搜索引擎中,如果做到折衷呢?基本的原则是,在系统性能可接受的前提下,尽量多召回有效结果,计算相关性时,将最相关的排在前面。
我们如何做到将合理减小粒度,增加有效召回,又如何做到将最好的排在最前呢?这里涉及到两个问题:紧密度与重要性。
既然粒度是衡量文本所含信息量的大小,那么紧密度就是描述文本所含信息紧密程度的量。再说的通俗一些,紧密度就是信息被人们表达和接受的稳定程度。稳定有两种解释,第一,稳定是相对于临时而言的。一般来说,如果信息是因为某些因素临时组合在一起,那就是不稳定的,即不紧密。比如许多动宾结构的短语(“过马路”,“踢足球”),定中结构的短语(“红苹果”,“豪华轿车”)。第二,稳定是相对于顺序不固定而言的。如果同样一个信息,内部的子信息顺序可以互换,那么这个词汇就不稳定,即不紧密。比如一些大粒度的词汇“鼠标护腕垫”、“护腕鼠标垫”。
由此可见,我们根据词汇的紧密程度,可以将结果中表述与查询表述的一致程度联系起来,作为计算相关性的一个因素。同样,我们也可以将紧密度作为减小粒度的依据之一,词汇越不紧密,我们就有理由将其拆分为更小的粒度。
短语的重要性,其实是短语子成分的重要性,有很多定义。其中一种被普遍接受的定义为其占短语完整含义的比例。一般情况下,偏正结构短语中,“正”的部分比较重要,比如“绿茶”中的“茶”,但也有例外,如“珊瑚虫”中的“珊瑚”。而主谓、动宾短语一般来说,都比较重要,如“打球”,“你说”。所以,短语的子成分重要性,不能仅靠语法来识别,而应综合各种因素来确定。
假设有了词汇的子成分重要性,那么就可以帮助判断将词汇粒度变小后的语义损失风险程度(注意,这里使用了“语义损失”,而不是“转义”,想一想为什么)。这也就回答了第四节末尾的问题:语义损失越小,越有可能召回相关结果。
五.结束语
本文介绍了搜索引擎中的粒度问题,重点讨论了搜索引擎与短语切分粒度的关系,并进一步探讨了短语的两个重要性质——紧密度和重要性。通过本文,读者应该能够大致明白搜索引擎中关于粒度的种种。当然,本文只是对搜索引擎的粒度问题开了一个头,怎么合理的处理好粒度、在不同场合使用何种粒度,都是需要我们继续深入研究的。
by xinzhou
来源: 百度搜索研发部官方博客

