-

浅谈网页搜索排序中的投票模型
前些天读了一本《选举的困境》,其中有一章,从美国的选举制度说起,介绍美国选举制度的不足,然后针对其不足,提出种种改善,然而每种改善都有其各自的问题,其中的变化很有趣。 先说美国选举制度,美国的总统选举是一种“赢者通吃”的方式,每个州根据其人口多少,有几十或几百的“州票”,州里的人对总统候选人进行选举,在某个州获得票最多的那个候选人,获得这个州所有的“州票”,然…... 塵風
塵風- 0
- 0
- 422
-
语音搜索的基础-语音识别
一直在想,假如有一天我们生活中的机器人像在很多科幻电影里面看到的那样,能够理解人类的语言,并能完成与人类的自然对话,是多爽的事情。语音的研究一直在试图解决这个问题。例如,语音到文字,即通常所说的语音识别,就试图将语音转换为文字,然后交给计算机进行后续的理解;而文字到语音,即语音合成,则试图将文字转换为声音,让人类可以听到。也许通过全世界语音界的科研和工程人员的努力,在不久的将来,我们真的可以和机器…...- 塵風
- 0
- 0
- 424
-

搜索背后的奥秘–浅谈语义主题计算
摘要: 两篇文档是否相关往往不只决定于字面上的词语重复,还取决于文字背后的语义关联。对语义关联的挖掘,可以让我们的搜索更加智能化。本文着重介绍了一个语义挖掘的利器:主题模型。主题模型是对文字隐含主题进行建模的方法。它克服了传统信息检索中文档相似度计算方法的缺点,并且能够在海量互联网数据中自动寻找出文字间的语义主题。近些年来各大互联网公司都开始了这方面的探索和尝试。就让我们看一下究竟吧。 关键词:主…...- 塵風
- 0
- 0
- 519
-
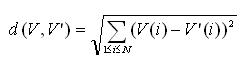
若无云,岂有风——词语语义相似度计算简介
诸多事物都要受到其周边事物的影响,进而改变自身的形态,甚至确立自己的存在——云动,方知风的存在。反映在人的眼中,则是云赋予了风的含义:若无云,岂有风? 0. 动机 武林高手经常从山川之间顿悟,并由山川之形变化出上乘武艺。风云之间的飘渺互动,实则也为实打实的科学、工程实践提供了指引。风是客观存在的,而只有籍由云,我们才能观察到它。在技术领域的日常工作中,诸如此类的例子数不胜数。而在自然语言语义的研究…...- 塵風
- 0
- 0
- 574
-

基于主特征空间相似度计算的切分算法及切分框架
我们为什么要切分? 说到切分(segmentation),大多数人最容易想到的就是中文分词。作为没有天然空格区分的语言,切词可以帮助计算机去索引文章,从而便于信息检索等方面。该部分主要用到了分词的一个方面:降低搜索引擎的性能消耗。我们常用的汉字有5000多个,常用词组是几十万个。在倒排索引中,如果用每个字做索引的话,那么会造成每个字对应的拉链非常长。所以我们一般会用词组来代替单个汉字建立索引。除此…...- 塵風
- 0
- 0
- 473
-

Boosting算法简介
一、Boosting算法的发展历史 Boosting算法是一种把若干个分类器整合为一个分类器的方法,在boosting算法产生之前,还出现过两种比较重要的将多个分类器整合为一个分类器的方法,即boostrapping方法和bagging方法。我们先简要介绍一下bootstrapping方法和bagging方法。 1)bootstrapping方法的主要过程 主要步骤: i)重复地从…...- 塵風
- 0
- 0
- 567
-
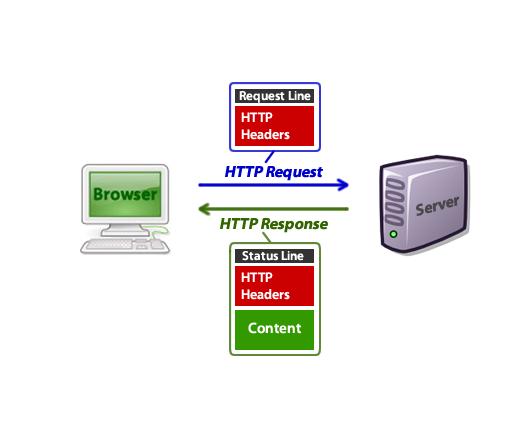
如何根据http请求信息区分访问用户的国家、语言信息
是不是见到google,facebook等大型专业网站的拥有不同的语言站群,可以不同语言间切换很给力?而我们只能羡慕嫉妒恨呢? 今天要介绍的就是如何识别不同国家,只需要简单几步,就能识别出来自不同国家的请求,使你的web应用更有国际范。 国家识别主要用到的是http header中的host,Accept-Language,cookie以及请求的url,ip等。 下面先温习下http header…...- 塵風
- 0
- 0
- 625
-
搜索引擎如何实现用户图片检索的需求满足
一、什么是需求满足 1.1 什么是需求满足 用户来搜索“章鱼 保罗”,就文本相关性而言,搜索引擎只要返回和“章鱼 保罗”内容相关的结果就可以了,这样用户是否满意呢? 用户甲:听说章鱼帝挂了,来看看最新结果,怎么全是8月份的,往后翻页中… 用户乙:今天同事们在讨论章鱼哥挂了,章鱼哥是啥?我又out了,来搜索一下章鱼帝生平事迹是啥,怎么全是最新的结果,没有章鱼哥的介绍啊,变换个query看看 …...- 塵風
- 0
- 0
- 461
-
地图检索 – 与众不同
前言: 半年前,和师弟在一起吃饭时,他忽然抬头,很好奇地问我:“为什么有了百度的大检索,百度地图还要自己做检索呢?”这个问题也一直伴随着我,后来有幸转入检索方向,不断摸索,也才有了这篇文章。 正文: 地图检索,顾名思义,是在地图里的检索。它与大检索大同小异,虽然在切词粒度、专名识别、拉链归并和rank等很多细节上与大检索有一定差异,然而真正让他与众不同、独具风采的,是地图领域所特有的空间位置信息。…...- 塵風
- 0
- 0
- 346
-
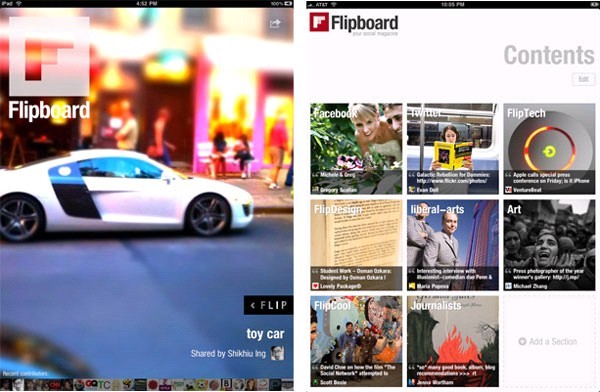
调研分享:Flipboard的使用特点和页面信息抽取机制
Flipboard是什么? 封面 封面 标榜为“社会化杂志”,是ipad上的app应用,可以订阅twitter和facebook上的人、群组和话题,可以订阅flipboard(后面简称flip)指定的杂志类别,也可以订阅高质量的媒体站点,通过这些渠道,用户可以获得包括新闻、图片、视频、博客、微博等形式的数据,通过触屏点击进行预览、翻屏等操作,操作简单,内容组织图文并茂,类似于传统的杂志。 内容…...- 塵風
- 0
- 0
- 1k
-
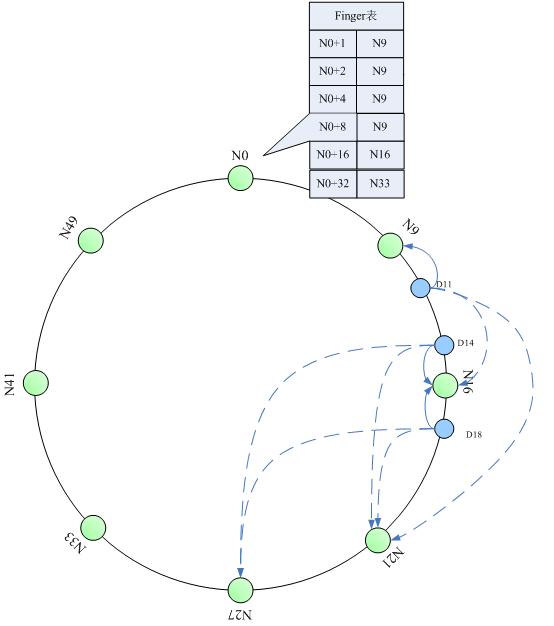
“分布式哈希”和“一致性哈希”的概念与算法实现
分布式哈希和一致性哈希是分布式存储和p2p网络中说的比较多的两个概念了。介绍的论文很多,这里做一个入门性质的介绍。 分布式哈希(DHT) 两个key point:每个节点只维护一部分路由;每个节点只存储一部分数据。从而实现整个网络中的寻址和存储。DHT只是一个概念,提出了这样一种网络模型。并且说明它是对分布式存储很有好处的。但具体怎么实现,并不是DHT的范畴。 一致性哈希: DHT的一…...- 塵風
- 0
- 0
- 523
-

浅析视频搜索中的清晰度识别过程
一、综述 随着互联网视频越来越多,人们迫切希望能够快速地从众多的视频中精准定位到一些高质量的视频。视频清晰度是评价视频质量的一个重要指标,特别是对于影视剧和动漫类视频来说,高清晰的视频能大大提升用户的体验。所以如何判断视频清晰度,识别出高清晰的视频对于用户和搜索引擎来说是非常有价值的。 和大多数评价机制一样,视频清晰度分为相对清晰度和绝对清晰度。相对清晰度可以理解为视频之间的清晰度排序,而…...- 塵風
- 0
- 0
- 807
-
基于hash计算的多层实验流量切分的实现
1. 背景介绍 站点新功能或者是站内新策略开发完毕之后,在全流量上线之前要评估新功能或者新策略的优劣,常用的评估方法是A-B测试,做法是在全量中抽样出两份小流量,分别走新策略分支和旧策略分支,通过对比这两份流量下的各指标的差异,我们可以评估出…...- 塵風
- 0
- 0
- 547
-
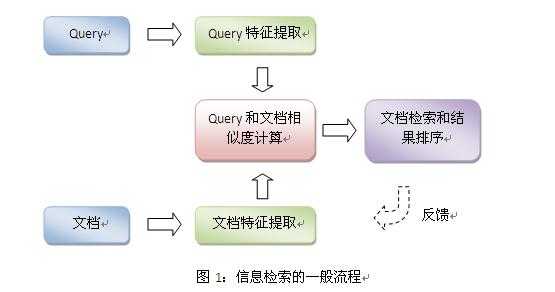
让搜索跨越语言的鸿沟——谈跨语言信息检索技术
跨语言信息检索,是信息检索领域中的一个研究课题。近10几年来,由于互联网的飞速发展,这方面的研究受到了学术界的广泛重视。将这项技术应用于搜索,可以帮助我们查找到更多的有用信息,例如外语相关页面、多语言页面以及语言无关的资源(如图片)等等。这些信息可以大大丰富搜索的结果,满足用户多样的需求。在跨语言信息检索的研究中,有一些研究成果已经趋于成熟,达到可以应用的状态。事实上,Yahoo和Google在5…...- 塵風
- 0
- 0
- 789
分类描述:
百度搜索研发部官方原介绍:百度搜索研发部官方博客(http://www.baidu-tech.com)由百度搜索研发部创建并维护。我们希望通过网络社区与关注搜索引擎及相关产品的技术人员交流互动,分享百度工程师研究的方向和取得的成果。
注:后貌似在2013年底关停。故而我在互联网中收集整理出部分和搜索引擎相关的内容转发出来,供大家查看。
这些内容对我们了解搜索引擎应该是极具价值的,尤其是当年(那时候我还没接触SEO呢),不过毕竟是时间很长的文章了,现在部分内容在百度资源平台的一些文档中也有提及。
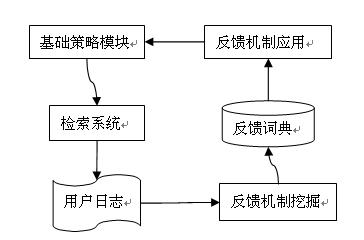

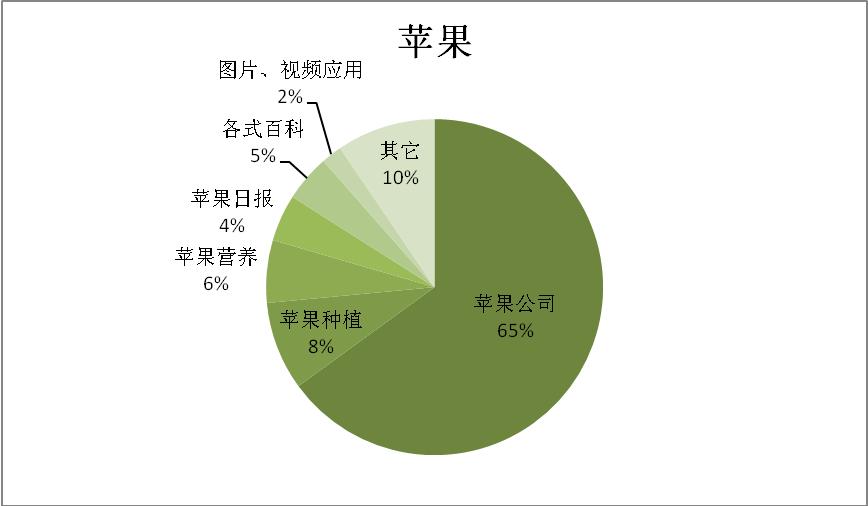

-
¥优惠劵使用时效:无法使用使用时效:
之前
使用时效:永久有效优惠劵ID:×