-
索引页链接补全机制的一种方法
背景 Spider位于搜索引擎数据流的最上游,负责将互联网上的资源采集到本地,提供给后续检索使用,是搜索引擎的最主要数据来源之一。spider系统的目标就是发现并抓取互联网中一切有价值的网页,为达到这个目标,首先就是发现有价值网页的链接,当前spider有多种链接发现机制来尽量快而全的发现资源链接,本文主要描述其中一种针对特定索引页的链接补全机制,并给出对这种特定类型的索引页面的建议处理规范用于优…... 塵風
塵風- 0
- 0
- 555
-

一种基于flex的可视化多层流量切分界面的实现
1. 背景介绍 策略开发人员在完成策略之后,在全流量上线之前要评估新的策略的优劣,常用的评估方法是A-B测试,做法是在全流量中抽样出两份小流量,分别走新策略分支和旧策略分支,通过对比这两份流量下的各指标的差异,我们可以评估出新策略的优劣,进而…...- 塵風
- 0
- 0
- 551
-
基于hash计算的多层实验流量切分的实现
1. 背景介绍 站点新功能或者是站内新策略开发完毕之后,在全流量上线之前要评估新功能或者新策略的优劣,常用的评估方法是A-B测试,做法是在全量中抽样出两份小流量,分别走新策略分支和旧策略分支,通过对比这两份流量下的各指标的差异,我们可以评估出…...- 塵風
- 0
- 0
- 549
-
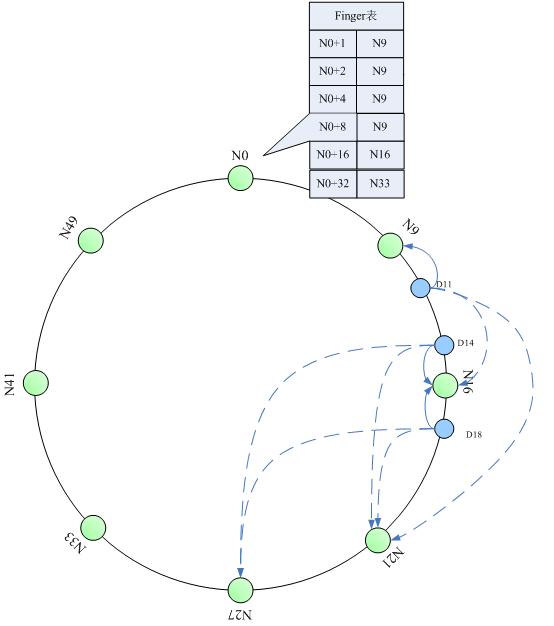
“分布式哈希”和“一致性哈希”的概念与算法实现
分布式哈希和一致性哈希是分布式存储和p2p网络中说的比较多的两个概念了。介绍的论文很多,这里做一个入门性质的介绍。 分布式哈希(DHT) 两个key point:每个节点只维护一部分路由;每个节点只存储一部分数据。从而实现整个网络中的寻址和存储。DHT只是一个概念,提出了这样一种网络模型。并且说明它是对分布式存储很有好处的。但具体怎么实现,并不是DHT的范畴。 一致性哈希: DHT的一…...- 塵風
- 0
- 0
- 525
-

搜索背后的奥秘–浅谈语义主题计算
摘要: 两篇文档是否相关往往不只决定于字面上的词语重复,还取决于文字背后的语义关联。对语义关联的挖掘,可以让我们的搜索更加智能化。本文着重介绍了一个语义挖掘的利器:主题模型。主题模型是对文字隐含主题进行建模的方法。它克服了传统信息检索中文档相似度计算方法的缺点,并且能够在海量互联网数据中自动寻找出文字间的语义主题。近些年来各大互联网公司都开始了这方面的探索和尝试。就让我们看一下究竟吧。 关键词:主…...- 塵風
- 0
- 0
- 523
-
智能算法在站点质量评级体系中的应用
互联网的迅速发展,海量Web数据的扑面而来,给搜索引擎技术带来了严峻的挑战,但同时也带来了新的机遇。从网页抓取的角度来看,同一站点往往包含质量相似的资源,对一个优质网站进行爬取,往往可以找到更多的优质资源。因此,我们希望对网站的质量进行评级,来反映资源的质量水平,从而影响spider的调度和收录。在以往的实践中,大体思路是根据人工调研出的经验构造出规则和阈值。发现问题后逐个打补丁、调阈值,来适应变…...- 塵風
- 0
- 0
- 507
-
JavaScript解析:让搜索引擎看到更真实的网页
长期以来,站长们选择使用JavaScript来实现网页的动态行为,这样做的原因是多种多样的,如加快页面的响应速度、降低网站流量、隐藏链接或者嵌入广告等。由于早期的搜索引擎没有相应的处理能力,导致在索引这类网页上往往出现问题,可能无法收录有价值的资源,也可能出现作弊。 引入JavaScript解析的目的,正是为了解决上述两方面的问题,其结果也就是使搜索引擎可以更为清晰的了解用户实际打开该网页时看到的…...- 塵風
- 0
- 0
- 496
-

基于主特征空间相似度计算的切分算法及切分框架
我们为什么要切分? 说到切分(segmentation),大多数人最容易想到的就是中文分词。作为没有天然空格区分的语言,切词可以帮助计算机去索引文章,从而便于信息检索等方面。该部分主要用到了分词的一个方面:降低搜索引擎的性能消耗。我们常用的汉字有5000多个,常用词组是几十万个。在倒排索引中,如果用每个字做索引的话,那么会造成每个字对应的拉链非常长。所以我们一般会用词组来代替单个汉字建立索引。除此…...- 塵風
- 0
- 0
- 477
-
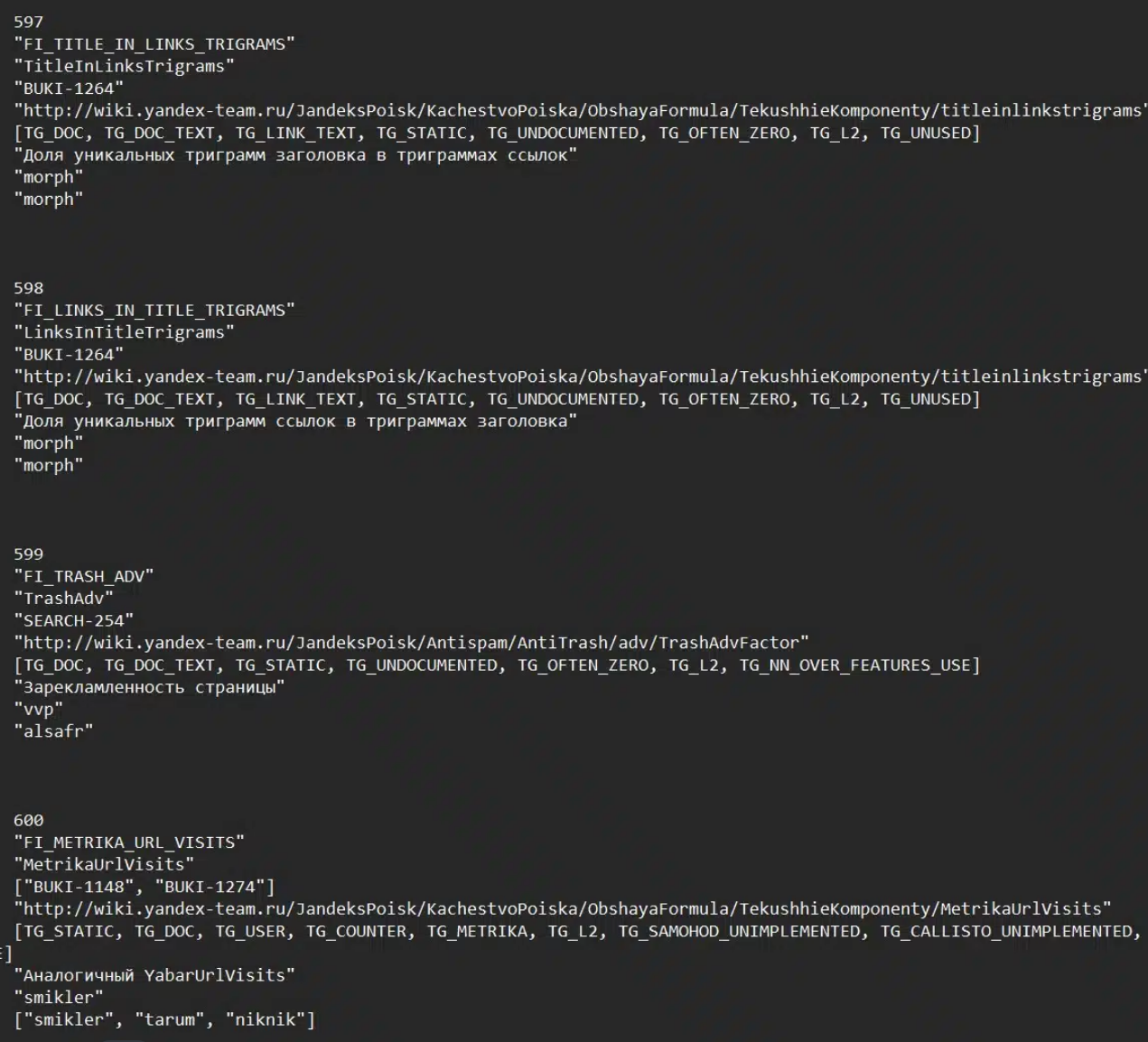
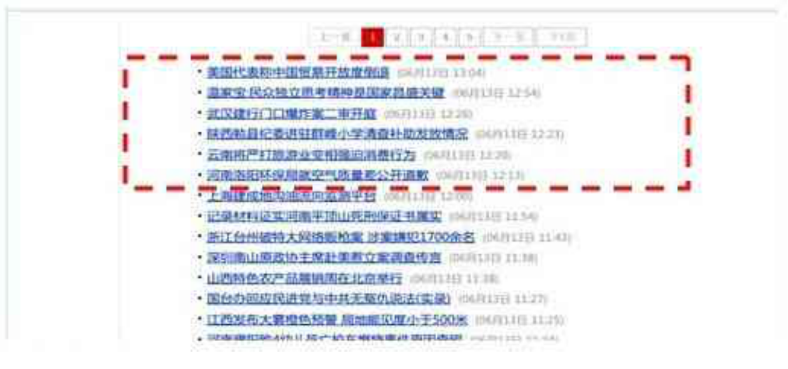
Yandex 搜索引擎源代码泄露1900+排名因子
2023 年 01 月,Yandex 的源代码在一个流行的黑客论坛上泄露。黑客发布了一个7.<> GB的文件,他们声称包含整个源代码减去其反垃圾邮件规则。 这里特别令人着迷的是,它包括一个他们的 1900+ 排名因素文件,供全世界查看。如果你想要下载这个资源,可自行到文章下发的GitHub资源、文档资源这两部分的链接中自行下载。 虽然Yandex不是Google(既它们之间是有区别的)…...- 塵風
- 0
- 0
- 469
-
搜索引擎如何实现用户图片检索的需求满足
一、什么是需求满足 1.1 什么是需求满足 用户来搜索“章鱼 保罗”,就文本相关性而言,搜索引擎只要返回和“章鱼 保罗”内容相关的结果就可以了,这样用户是否满意呢? 用户甲:听说章鱼帝挂了,来看看最新结果,怎么全是8月份的,往后翻页中… 用户乙:今天同事们在讨论章鱼哥挂了,章鱼哥是啥?我又out了,来搜索一下章鱼帝生平事迹是啥,怎么全是最新的结果,没有章鱼哥的介绍啊,变换个query看看 …...- 塵風
- 0
- 0
- 464
-
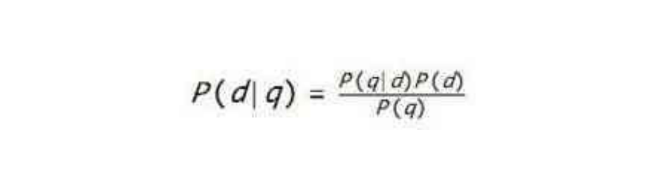
以求医为例谈搜索引擎排序算法的基础原理
我们向搜索引擎提交一个查询,搜索引擎会从先到后列出大量的结果,这些结果排序的标准是什么呢?这个看似简单的问题,却是信息检索专家们研究的核心难题之一。 为了说明这个问题,我们来研究一个比搜索引擎更加古老的话题:求医。比如,如果我牙疼,应该去看怎样的医生呢?假设我只有三种选择: A医生,既治眼病,又治胃病;B医生,既治牙病,又治胃病,还治眼病;C医生,专治牙病。 A医生肯定不在考虑之列。B医生和C医生…...- 塵風
- 0
- 0
- 463
-
浅谈网页搜索排序中的投票模型
前些天读了一本《选举的困境》,其中有一章,从美国的选举制度说起,介绍美国选举制度的不足,然后针对其不足,提出种种改善,然而每种改善都有其各自的问题,其中的变化很有趣。 先说美国选举制度,美国的总统选举是一种“赢者通吃”的方式,每个州根据其人口多少,有几十或几百的“州票”,州里的人对总统候选人进行选举,在某个州获得票最多的那个候选人,获得这个州所有的“州票”,然…...- 塵風
- 0
- 0
- 428
-
语音搜索的基础-语音识别
一直在想,假如有一天我们生活中的机器人像在很多科幻电影里面看到的那样,能够理解人类的语言,并能完成与人类的自然对话,是多爽的事情。语音的研究一直在试图解决这个问题。例如,语音到文字,即通常所说的语音识别,就试图将语音转换为文字,然后交给计算机进行后续的理解;而文字到语音,即语音合成,则试图将文字转换为声音,让人类可以听到。也许通过全世界语音界的科研和工程人员的努力,在不久的将来,我们真的可以和机器…...- 塵風
- 0
- 0
- 427
-
下载1个资源
 下载1个资源
下载1个资源
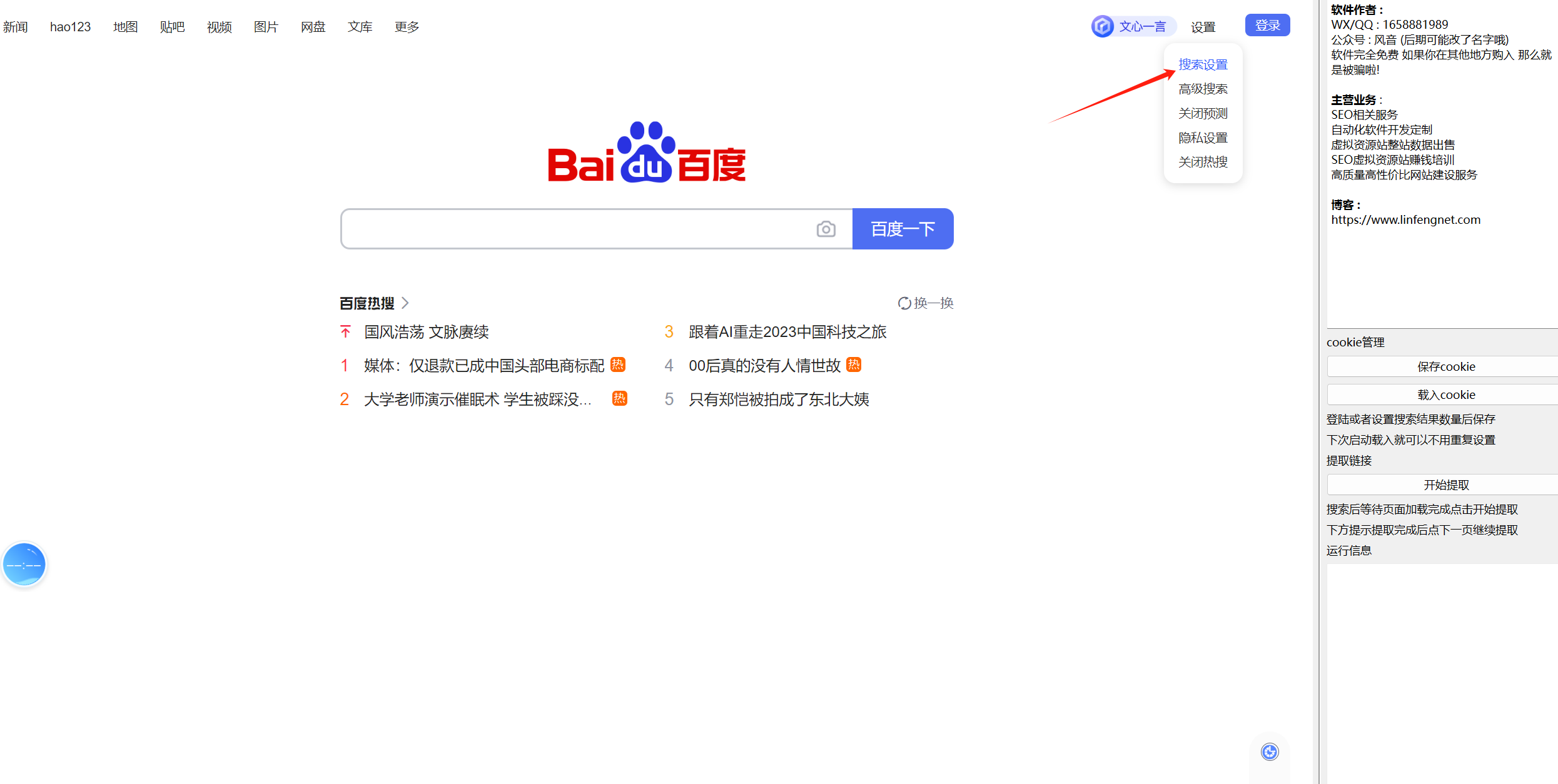
百度已收录404链接自动提取软件+使用教程-免费
软件介绍 现在有非常多的网站被黑然后搜索被搜索引擎收录了色情赌博一类的垃圾信息,我们站点被黑处理完成后把这些垃圾信息链接设置为404就需要对这些已经收录的链接进行提取,然后提交到百度资源平台删除,但是对于大部分没有技术基础的小伙伴来说,都只能一个个手动去复制,这样太过于麻烦了,所有开发了这个软件分享给大家。 关于处理流程的教程,我之前也分享了相关文章,如果你有需要,也可以查看: 网站被黑,被搜索引…...- 塵風
- 0
- 2
- 420
-
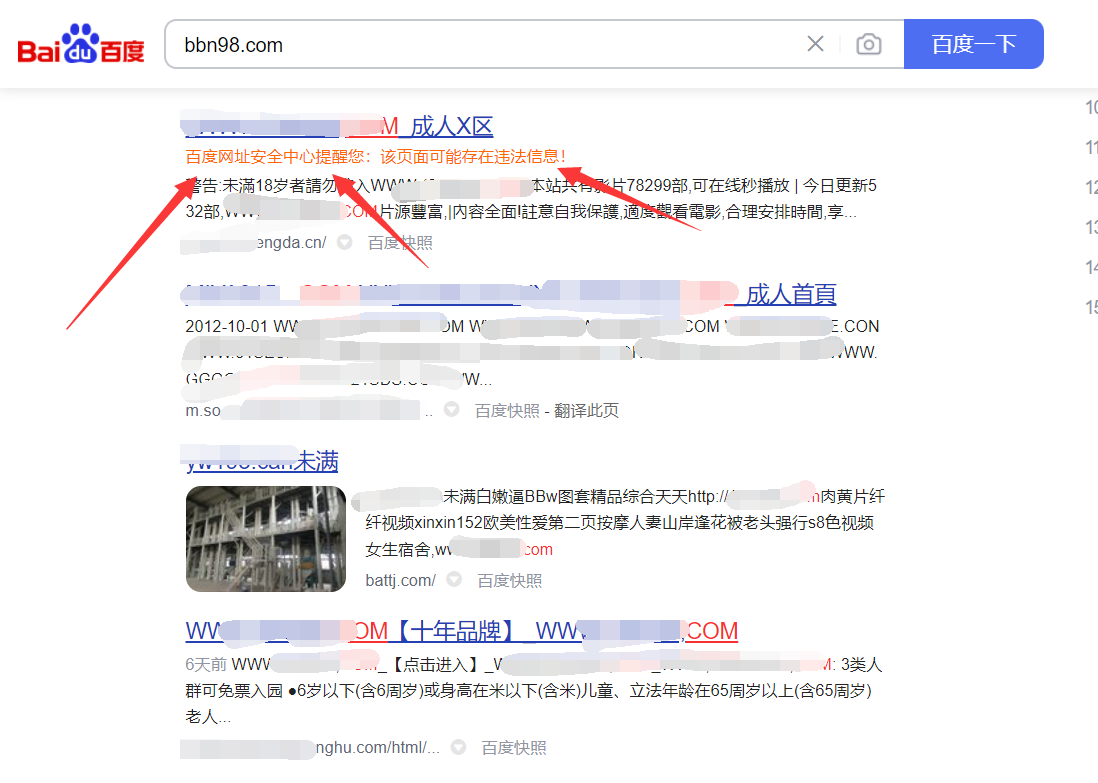
百度显示风险网站怎么办?
内容摘要: 百度搜索结果页面显示网站是风险网站,这种情况一般是网站出现了违规内容(自己没操作就是被黑了),解决办法:先排除自身网站违规内容和处理相关漏洞,不懂技术可以找技术公司解决,可以联系我们林风网络。处理完自身网站内容后,到百度网址安全中心申诉然后等待完成就行。 下面是详细教程: 问题原因: 百度提示网站存在风险这个问题已经好久没遇到了,出现这种情况多是因为网站被黑,被挂上了菠菜赌博类的违法违…... 靓仔编辑
靓仔编辑- 0
- 0
- 388


-
¥优惠劵使用时效:无法使用使用时效:
之前
使用时效:永久有效优惠劵ID:×